解题思路
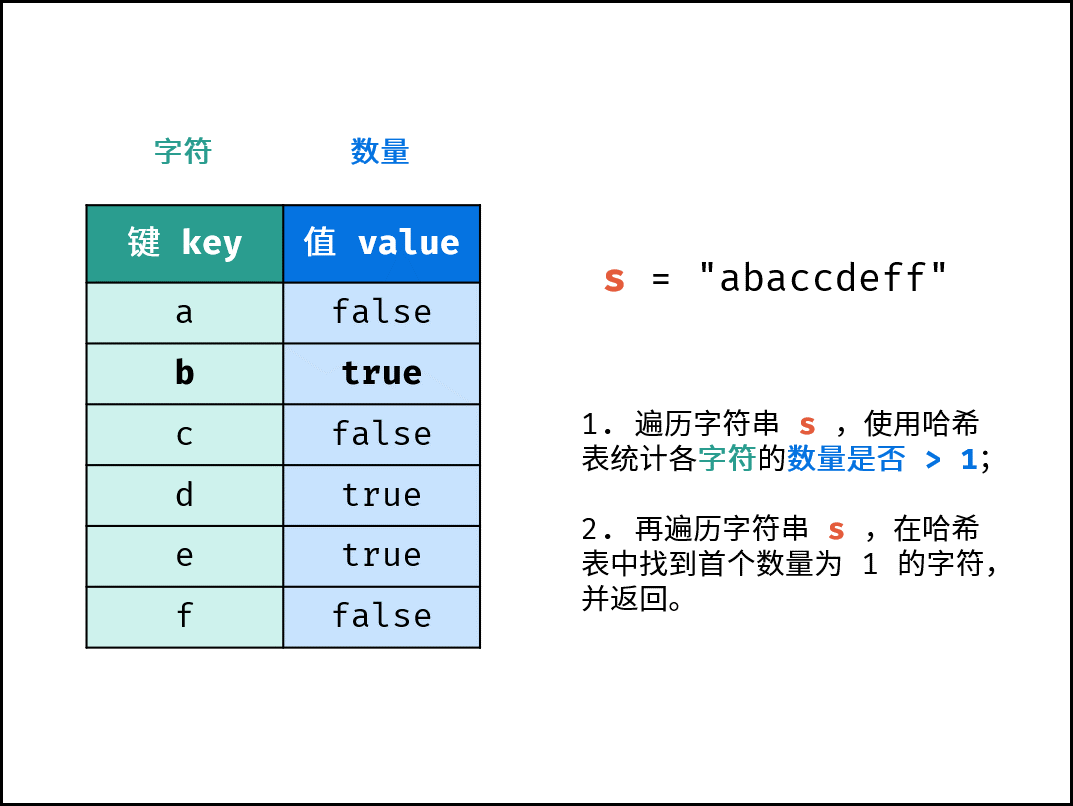
- 遍历字符串
s,使用哈希表统计 “各字符数量是否 $> 1$ ”。 - 再遍历字符串
s,在哈希表中找到首个 “数量为 $1$ 的字符”,并返回。
算法流程:
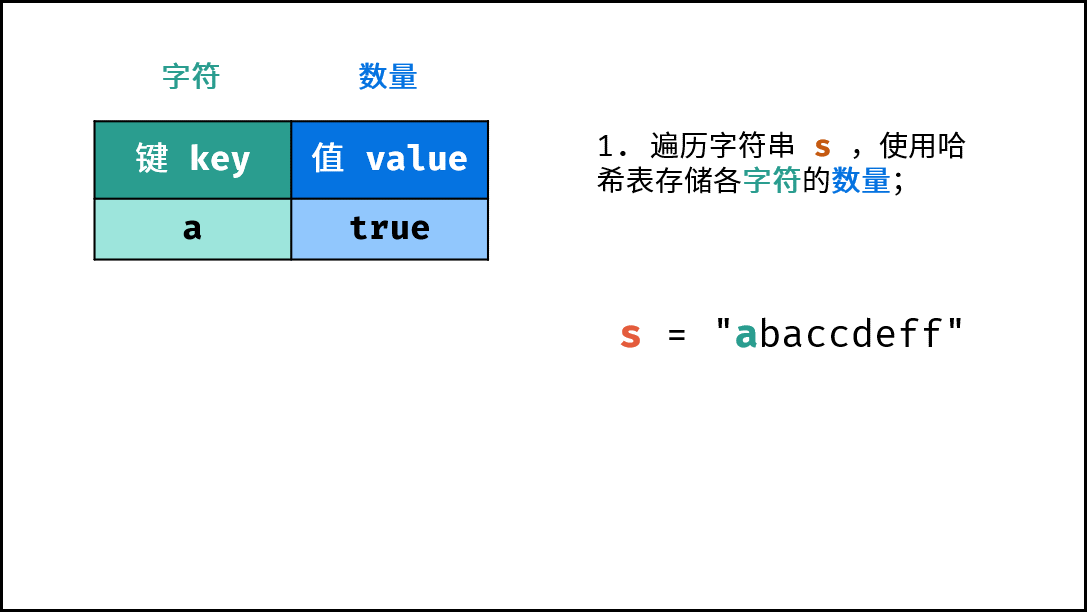
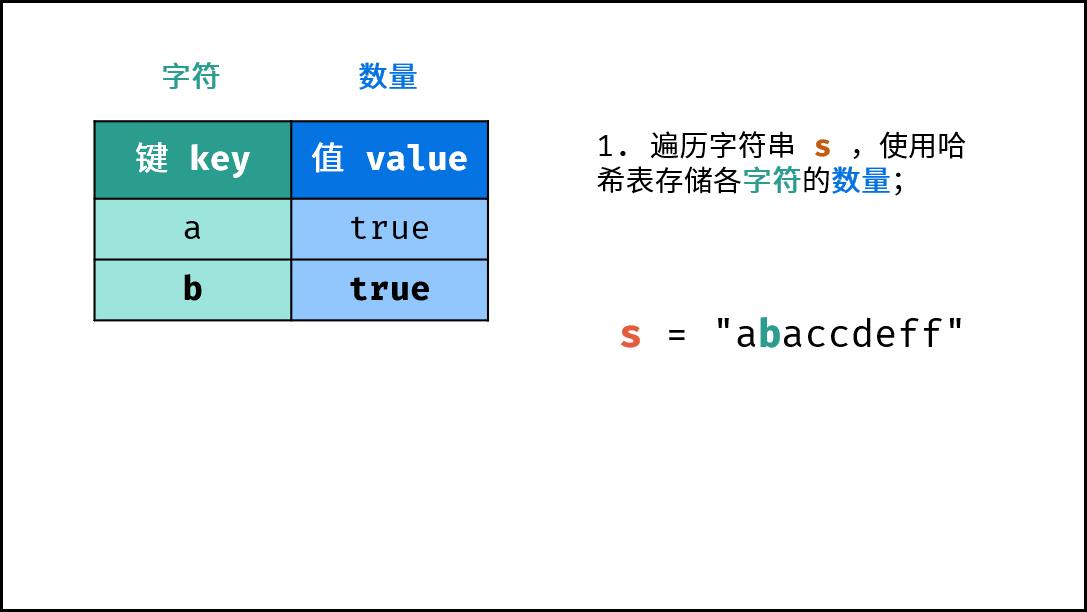
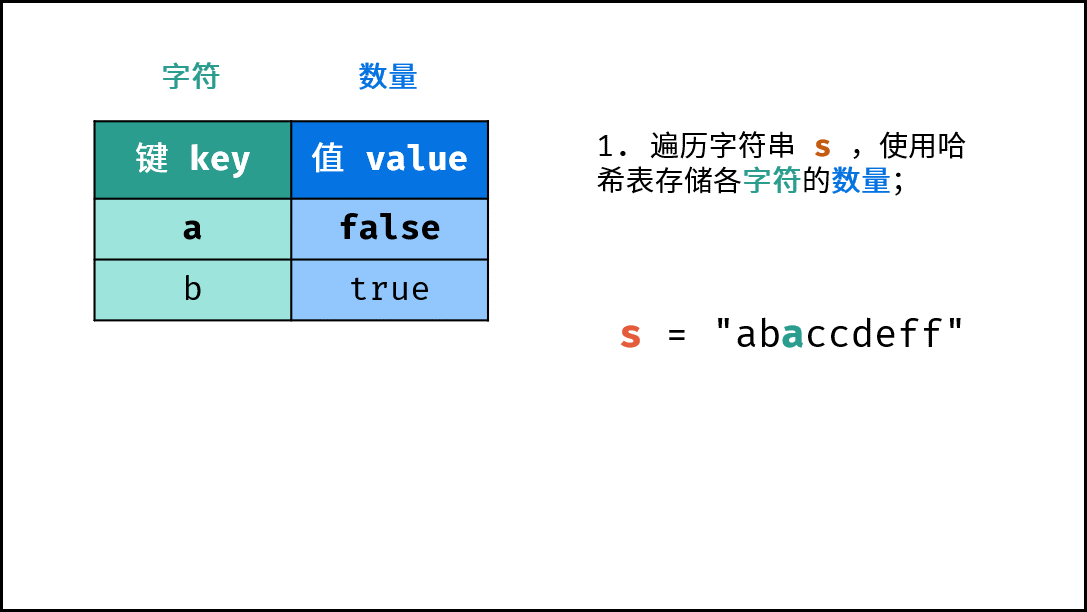
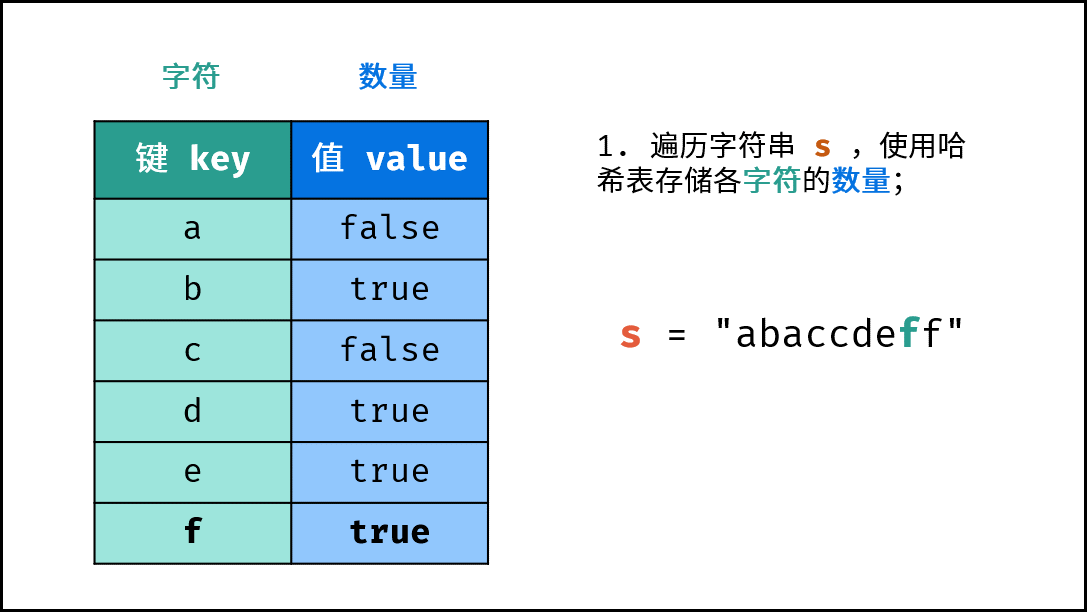
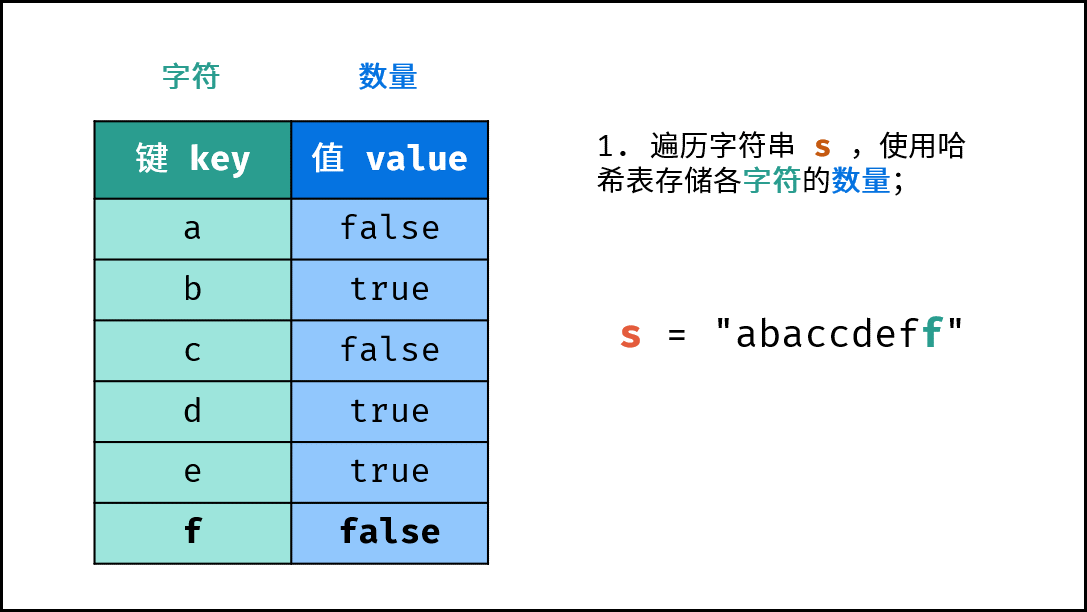
- 初始化: 字典 (Python)、HashMap(Java)、map(C++),记为
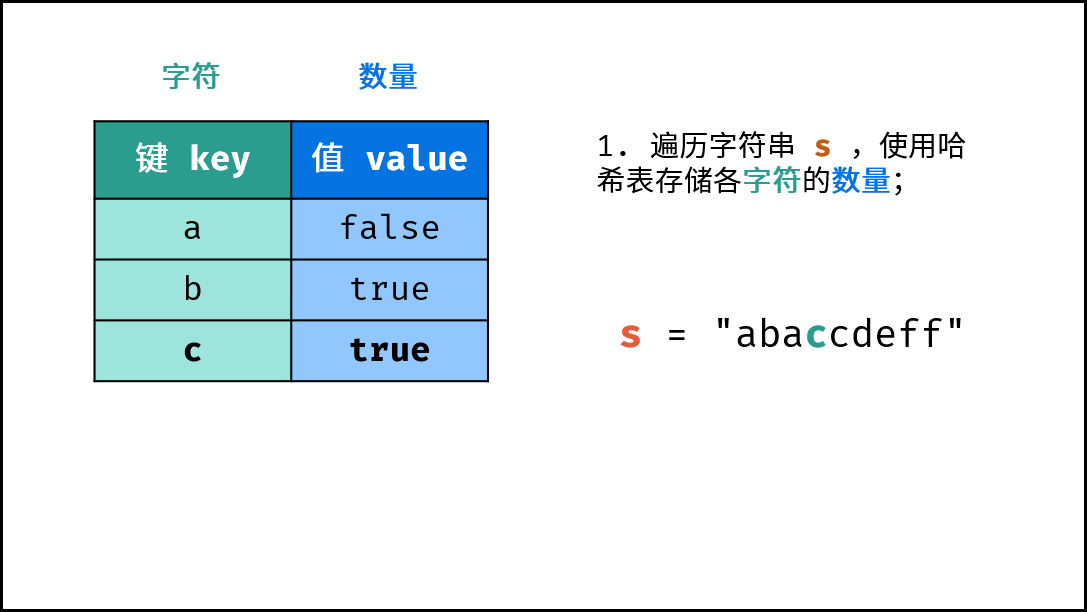
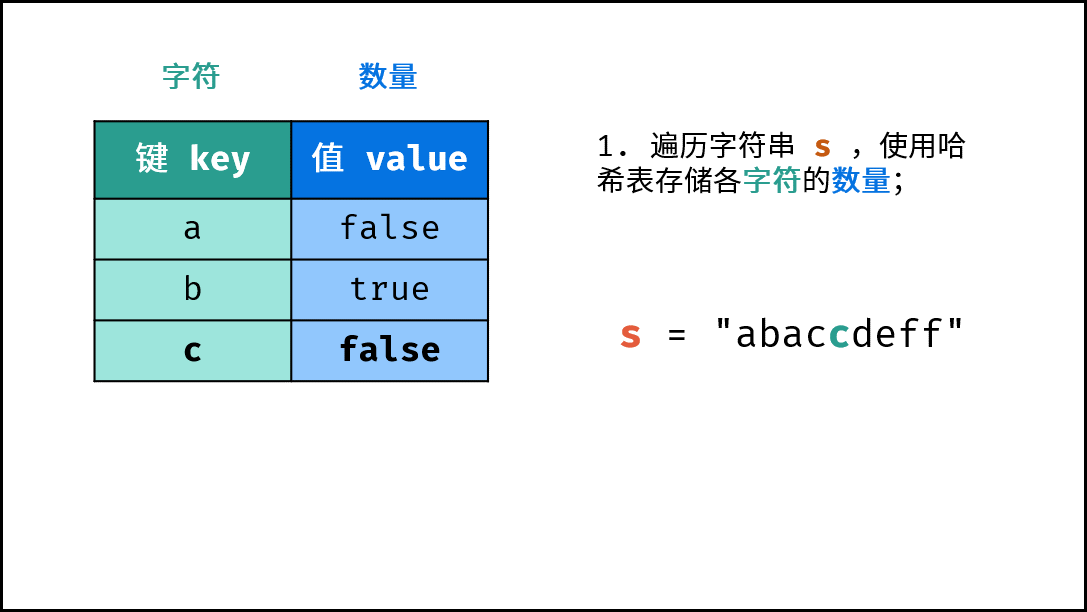
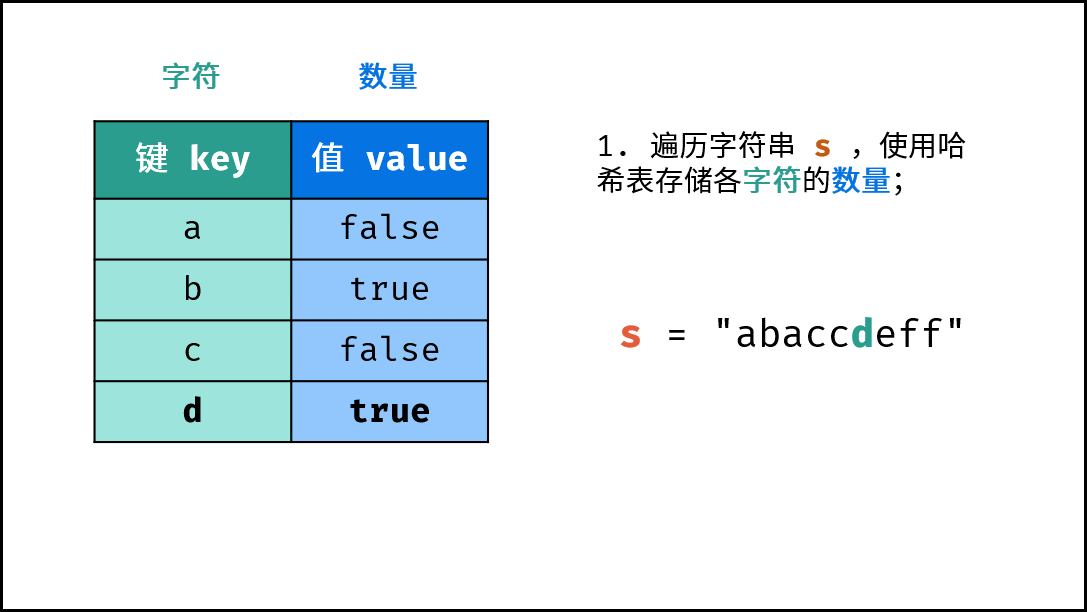
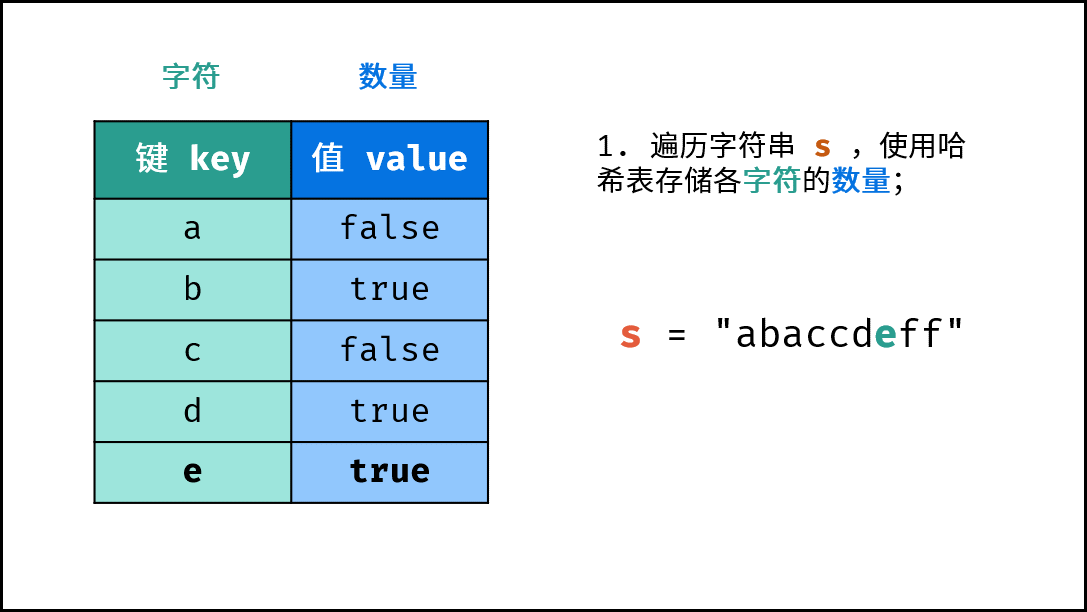
dic。 - 字符统计: 遍历字符串
s中的每个字符c。- 若
dic中 不包含 键(key)c:则向dic中添加键值对(c, True),代表字符c的数量为 $1$ 。 - 若
dic中 包含 键(key)c:则修改键c的键值对为(c, False),代表字符c的数量 $> 1$ 。
- 若
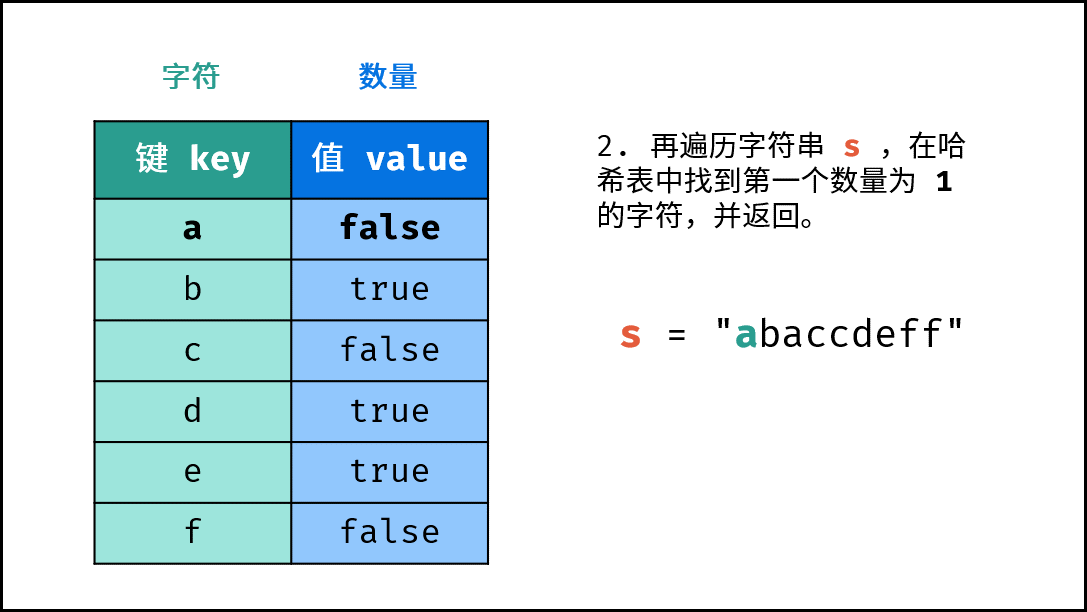
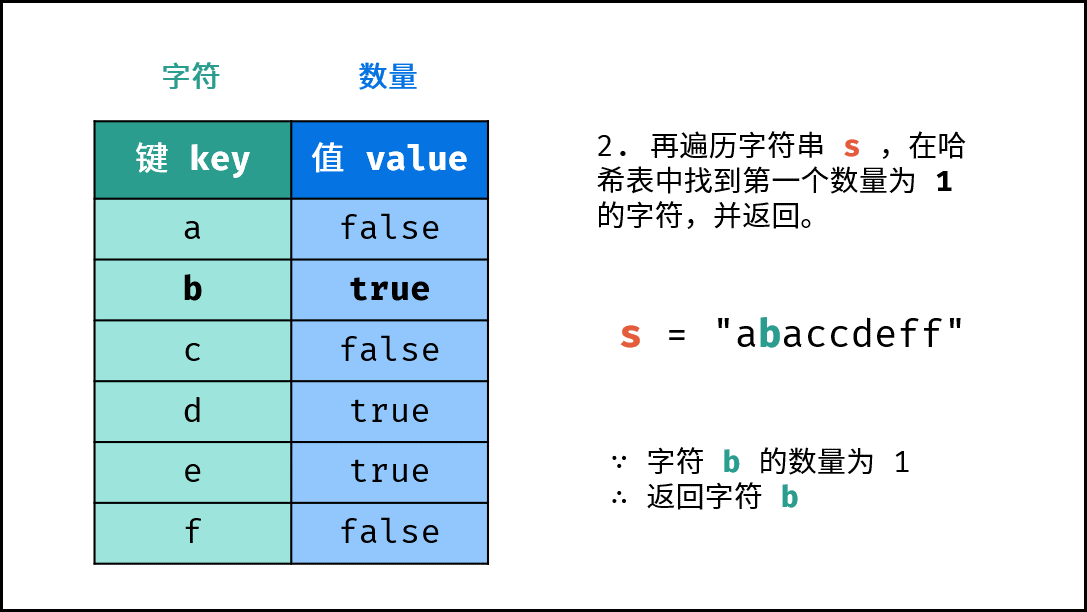
- 查找数量为 $1$ 的字符: 遍历字符串
s中的每个字符c。- 若
dic中键c对应的值为True:,则返回其索引。 - 否则,返回
-1,代表不存在数量为 $1$ 的字符。
- 若
< ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, >
>
代码:
Python 代码中的 not c in dic 整体为一个布尔值; c in dic 为判断字典中是否含有键 c 。
Python
class Solution:
def firstUniqChar(self, s: str) -> int:
dic = {}
for c in s:
dic[c] = not c in dic
for i, c in enumerate(s):
if dic[c]: return i
return -1Java
class Solution {
public int firstUniqChar(String s) {
HashMap<Character, Boolean> dic = new HashMap<>();
char[] sc = s.toCharArray();
for(char c : sc)
dic.put(c, !dic.containsKey(c));
for(int i = 0; i < sc.length; i++)
if(dic.get(sc[i])) return i;
return -1;
}
}C++
class Solution {
public:
int firstUniqChar(string s) {
unordered_map<char, bool> dic;
for(char c : s)
dic[c] = dic.find(c) == dic.end();
for(int i = 0; i < s.size(); i++)
if(dic[s[i]]) return i;
return -1;
}
};复杂度分析:
- 时间复杂度 $O(N)$ : $N$ 为字符串
s的长度;需遍历s两轮,使用 $O(N)$ ;HashMap 查找操作的复杂度为 $O(1)$ 。 - 空间复杂度 $O(1)$ : 由于题目指出
s只包含小写字母,因此最多有 26 个不同字符,HashMap 存储需占用 $O(26) = O(1)$ 的额外空间。