解题思路:
设两字符串 $s_1$ , $s_2$ ,则两者互为重排的「充要条件」为:两字符串 $s_1$ , $s_2$ 包含的字符是一致的,即 $s_1$ , $s_2$ 所有对应字符数量都相同,仅排列顺序不同。
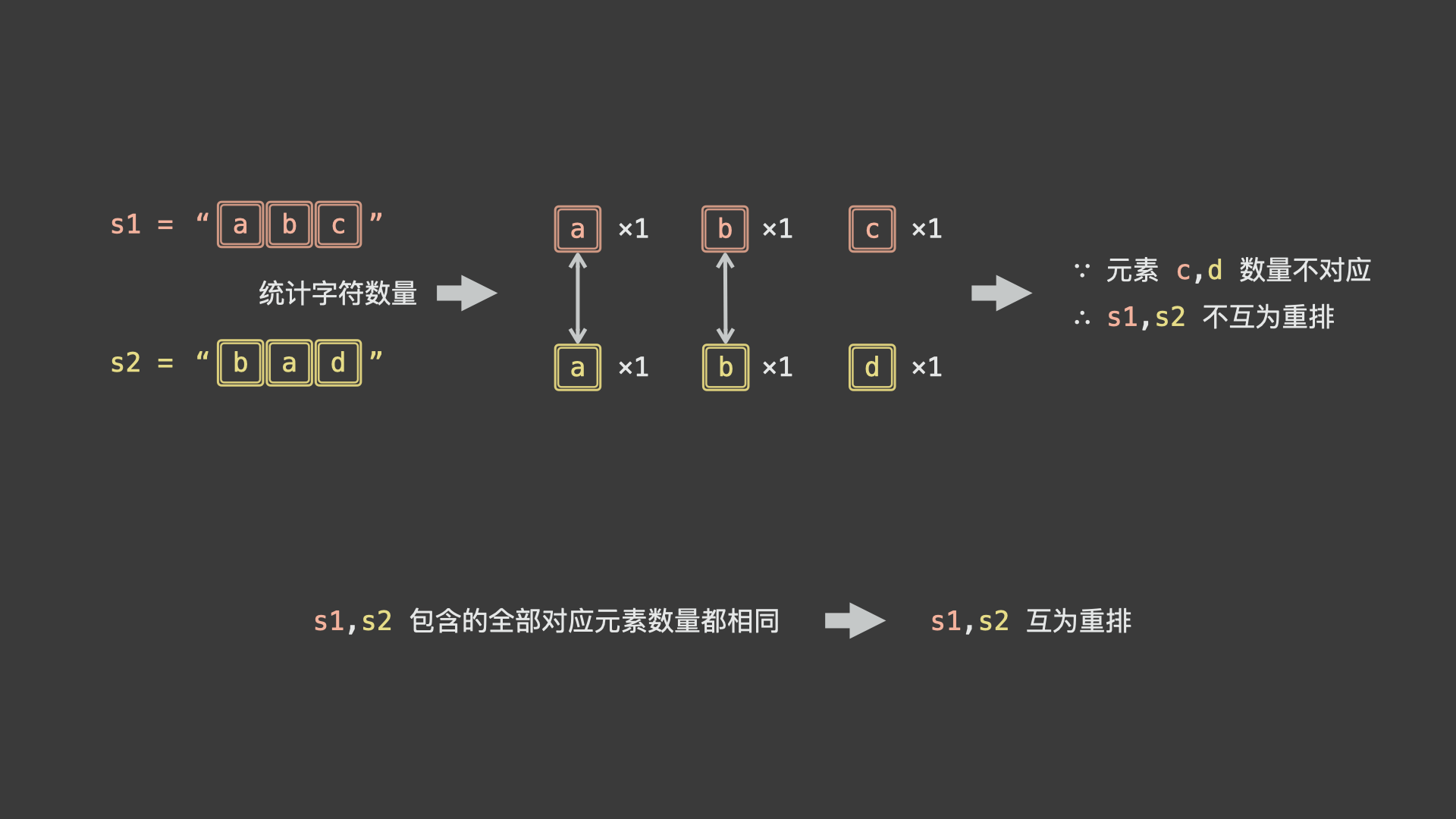
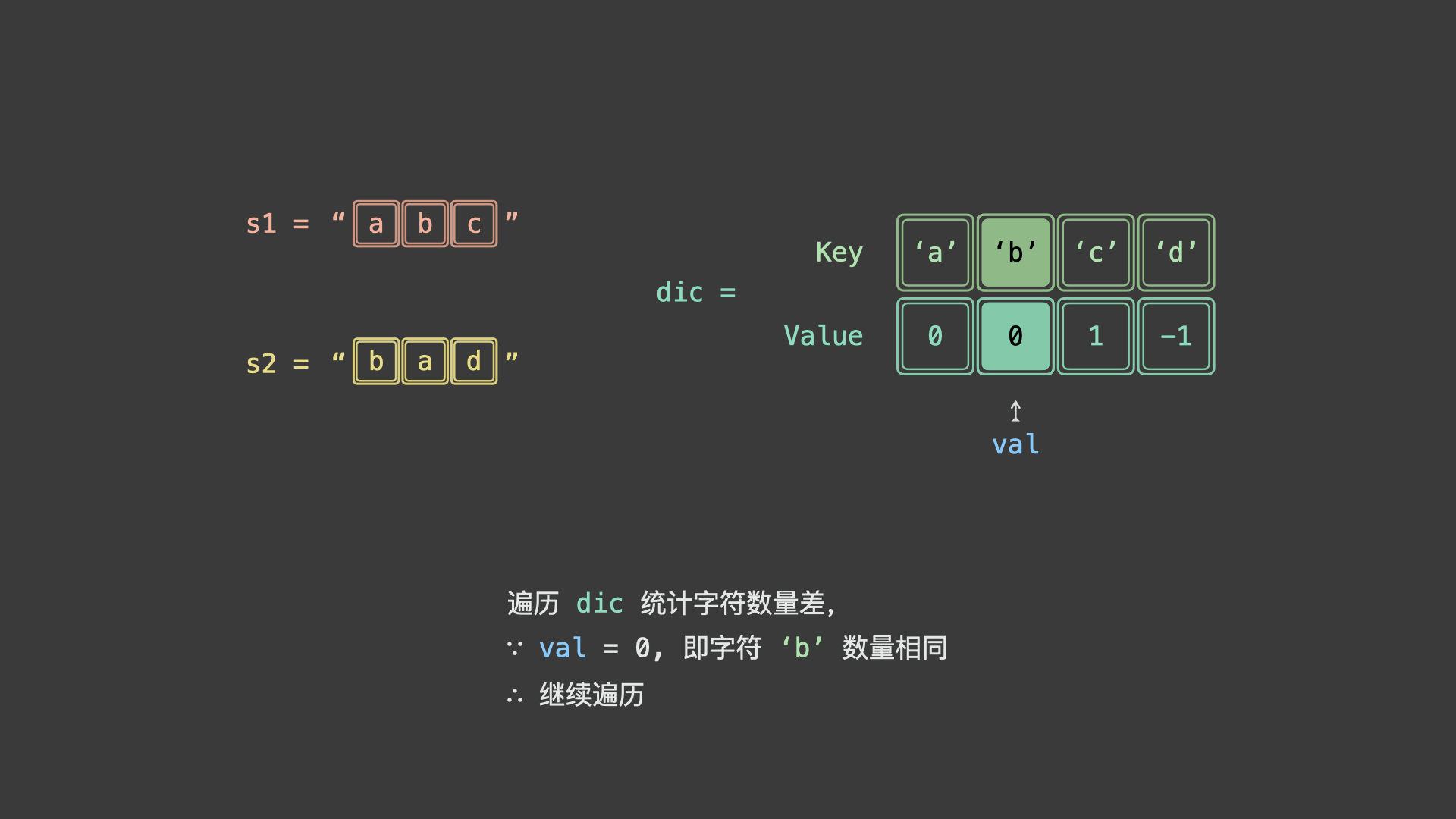
根据以上分析,可借助「哈希表」分别统计 $s_1$ , $s_2$ 中各字符数量 key: 字符, value: 数量 ,分为以下情况:
- 若 $s_1$ , $s_2$ 字符串长度不相等,则「不互为重排」;
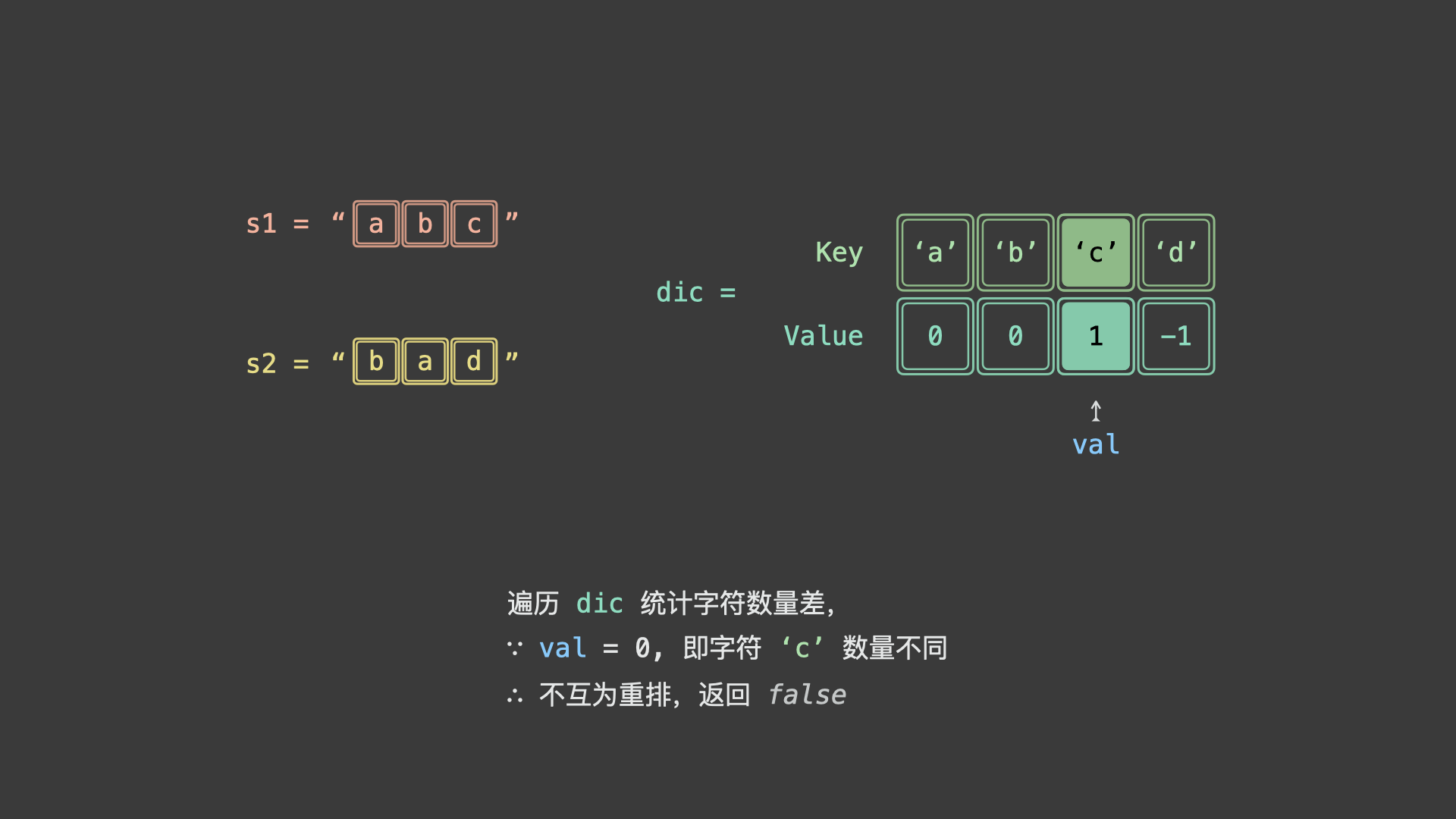
- 若 $s_1$ , $s_2$ 某对应字符数量不同,则「不互为重排」;
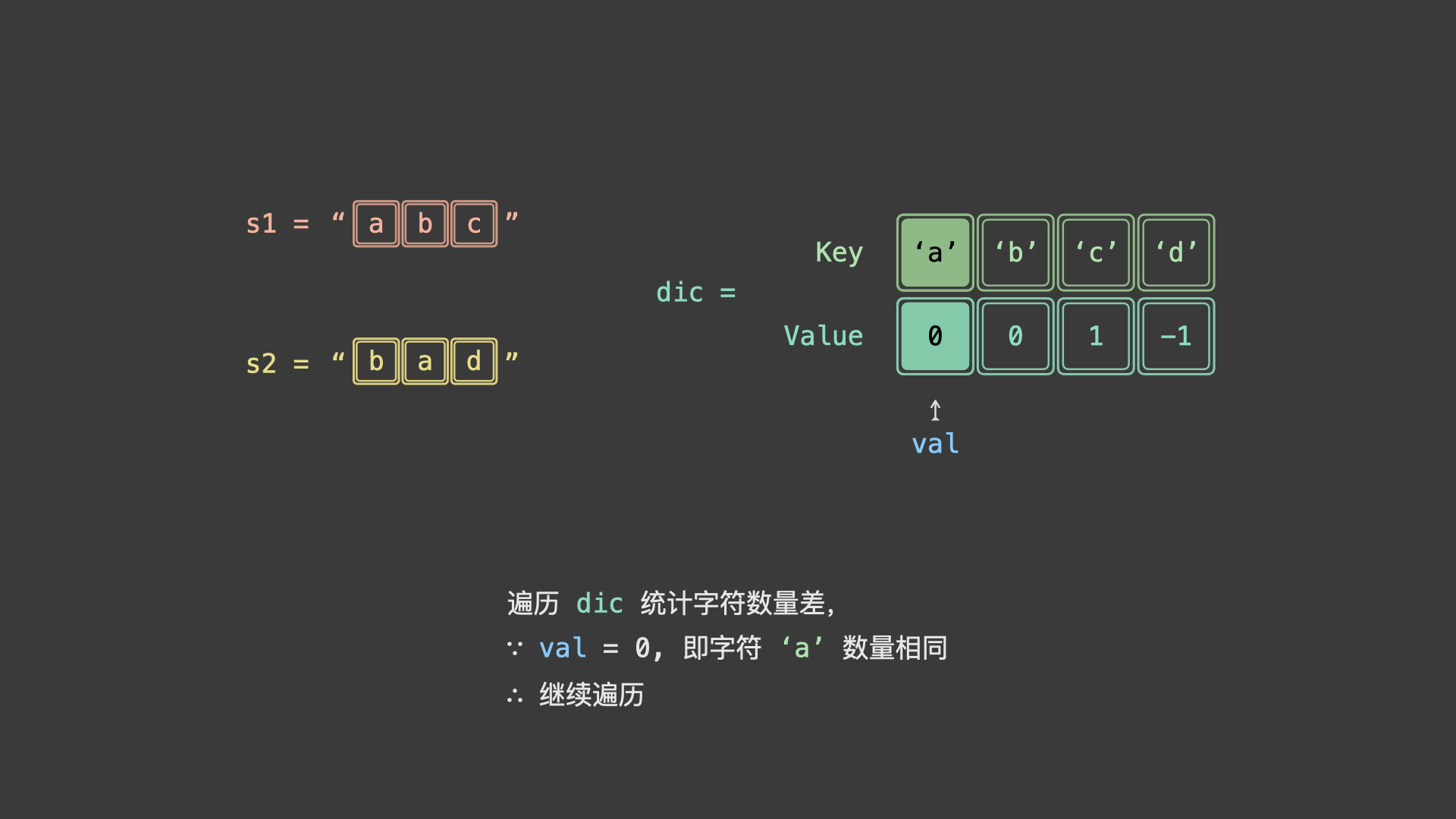
- 否则,若 $s_1$ , $s_2$ 所有对应字符数量都相同,则「互为重排」;
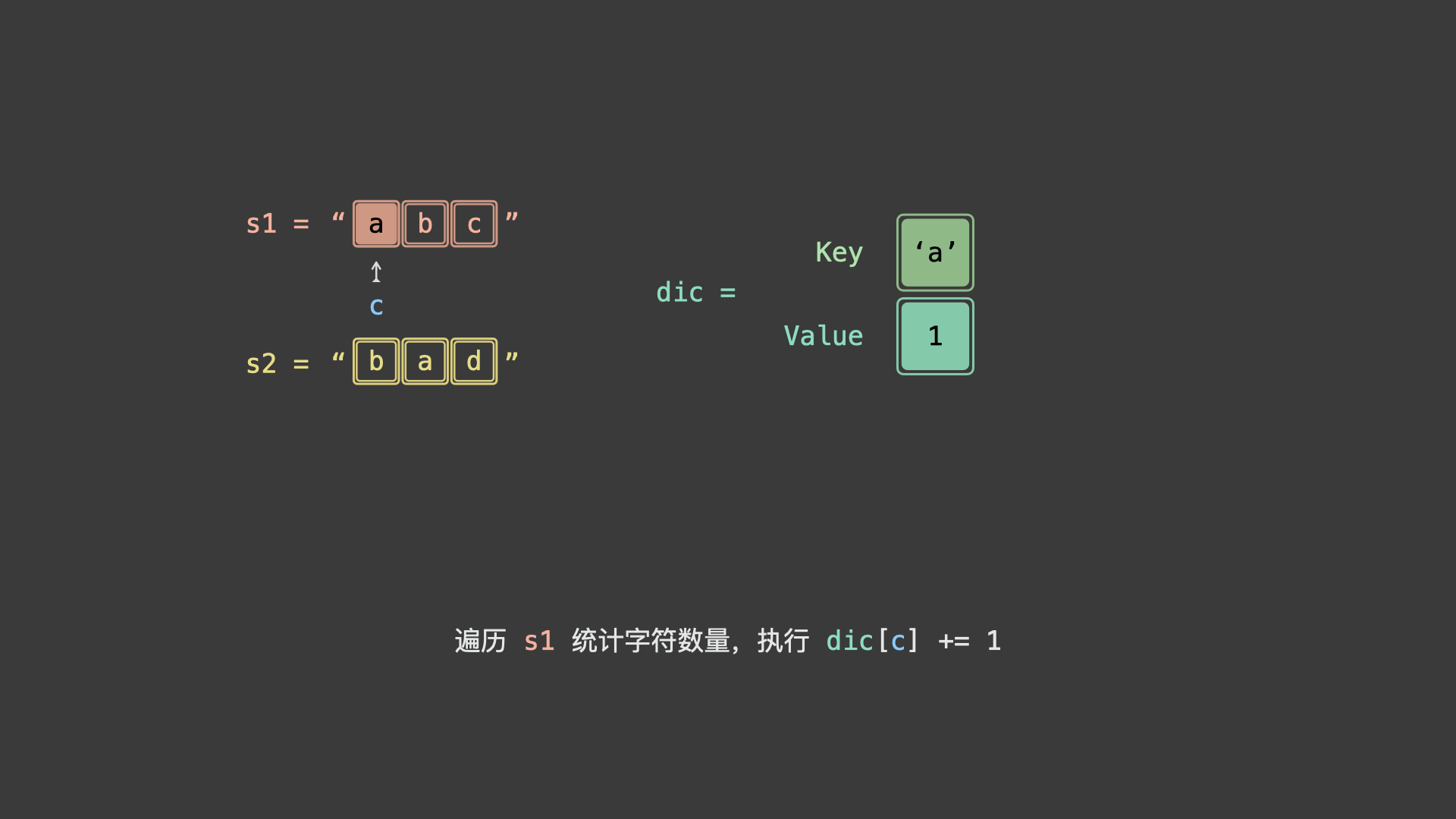
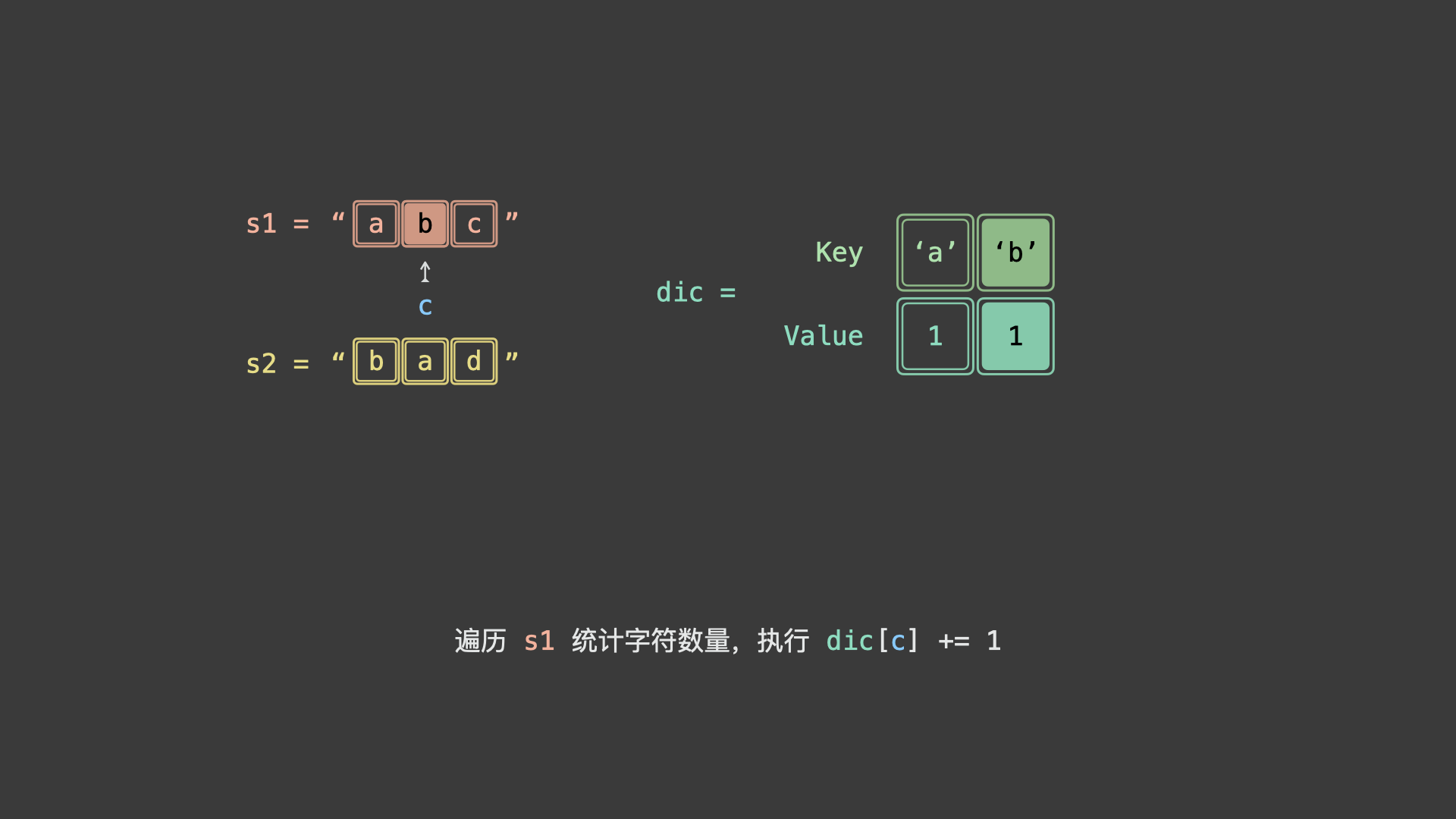
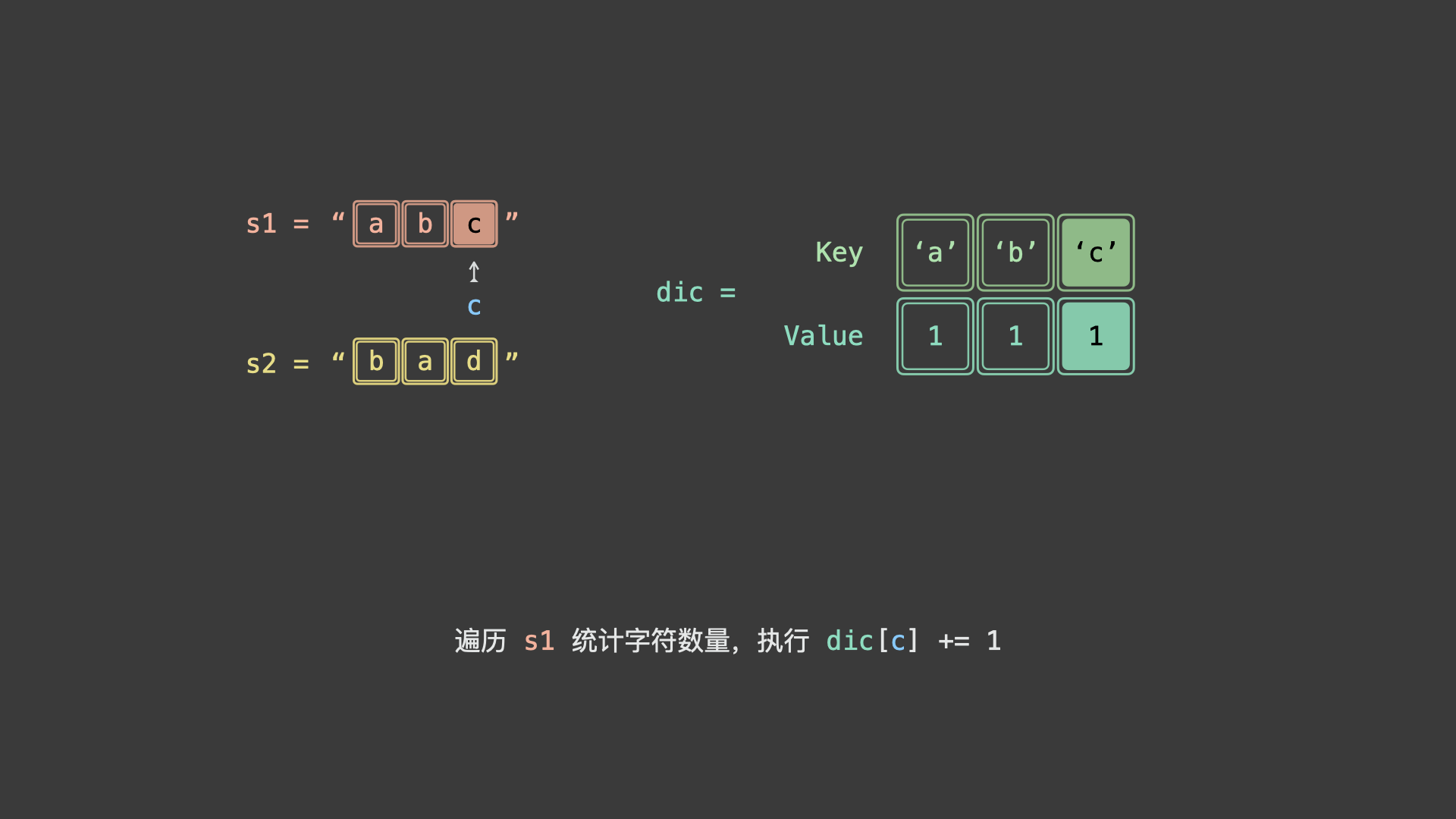
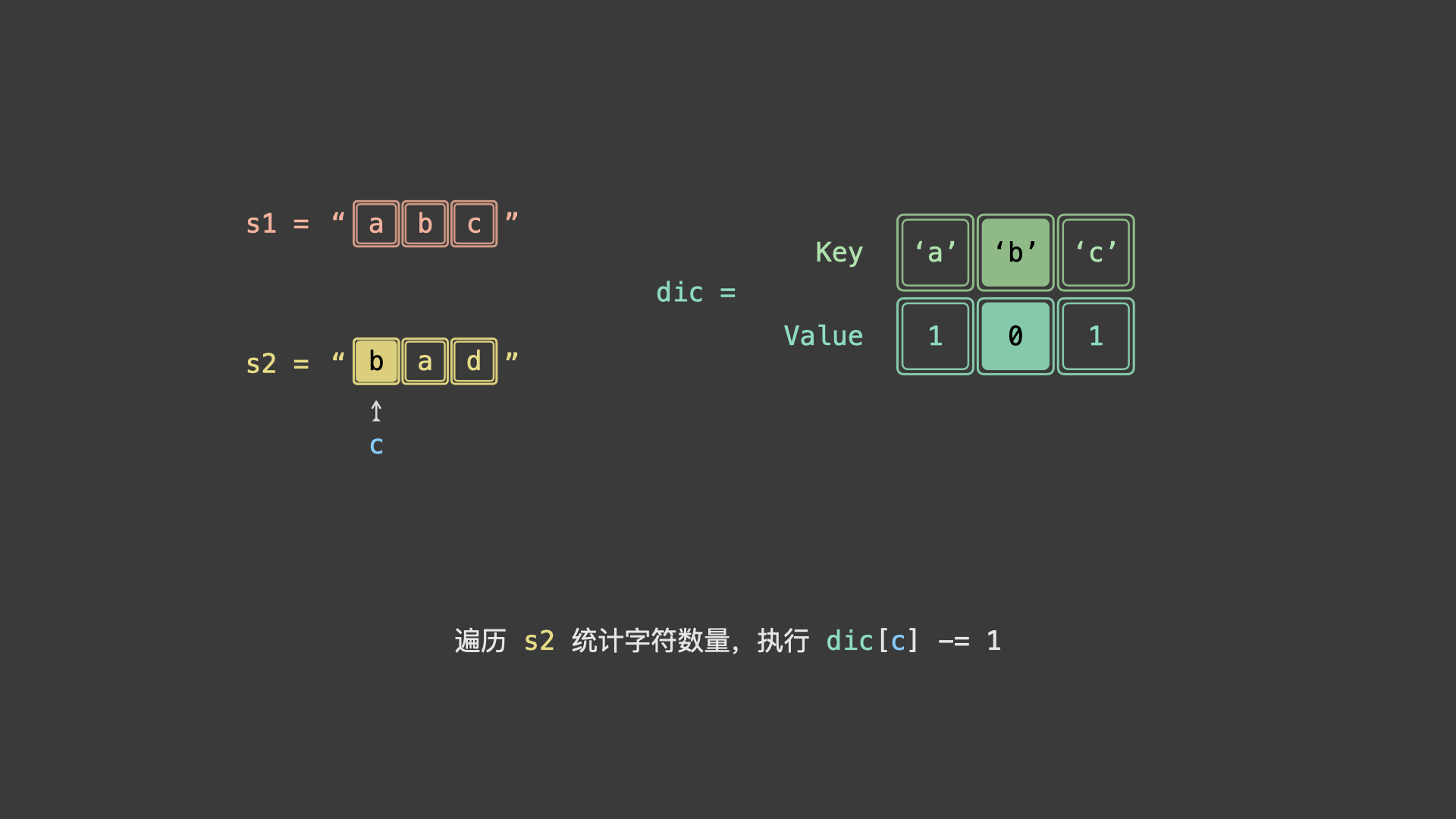
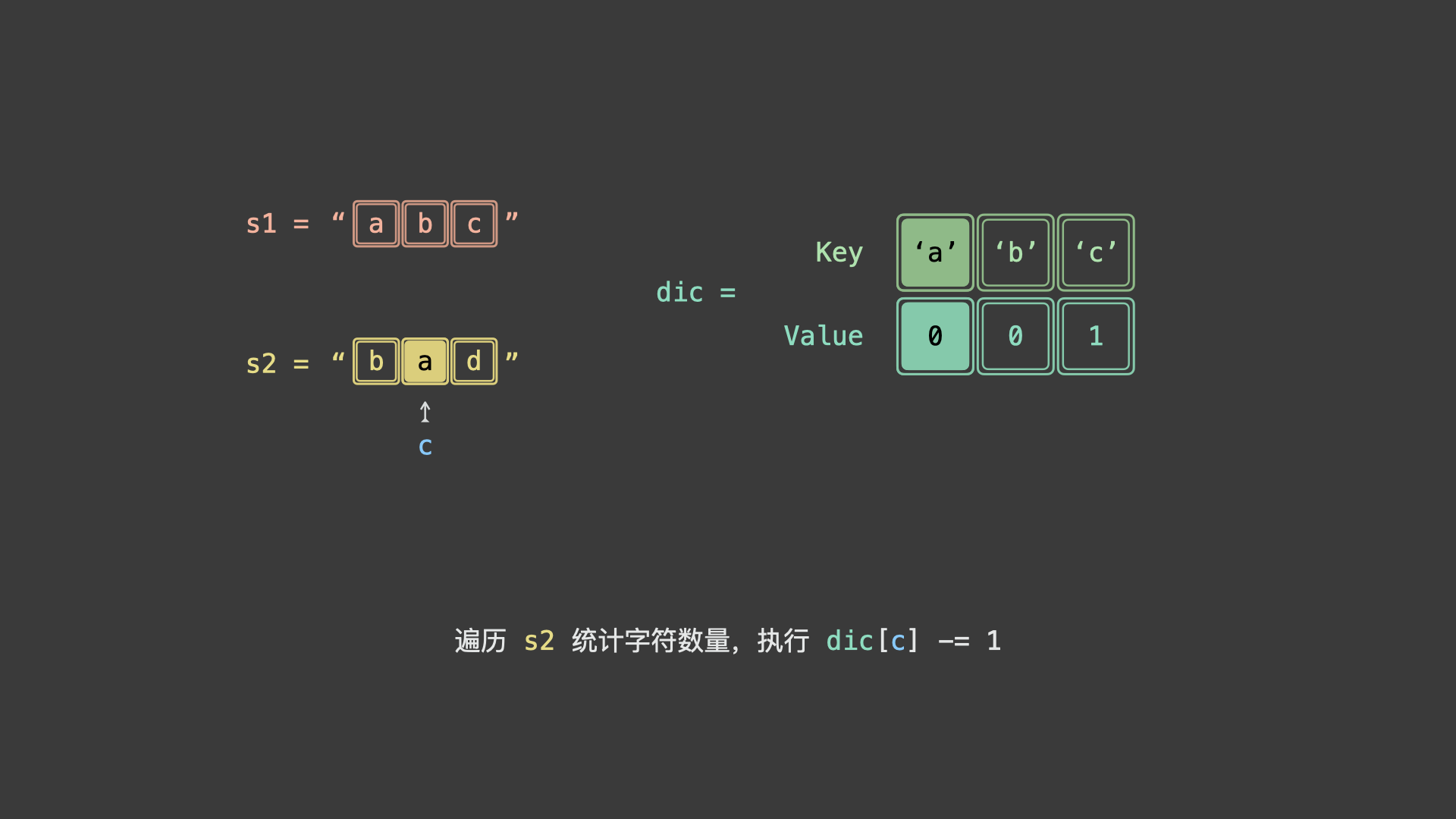
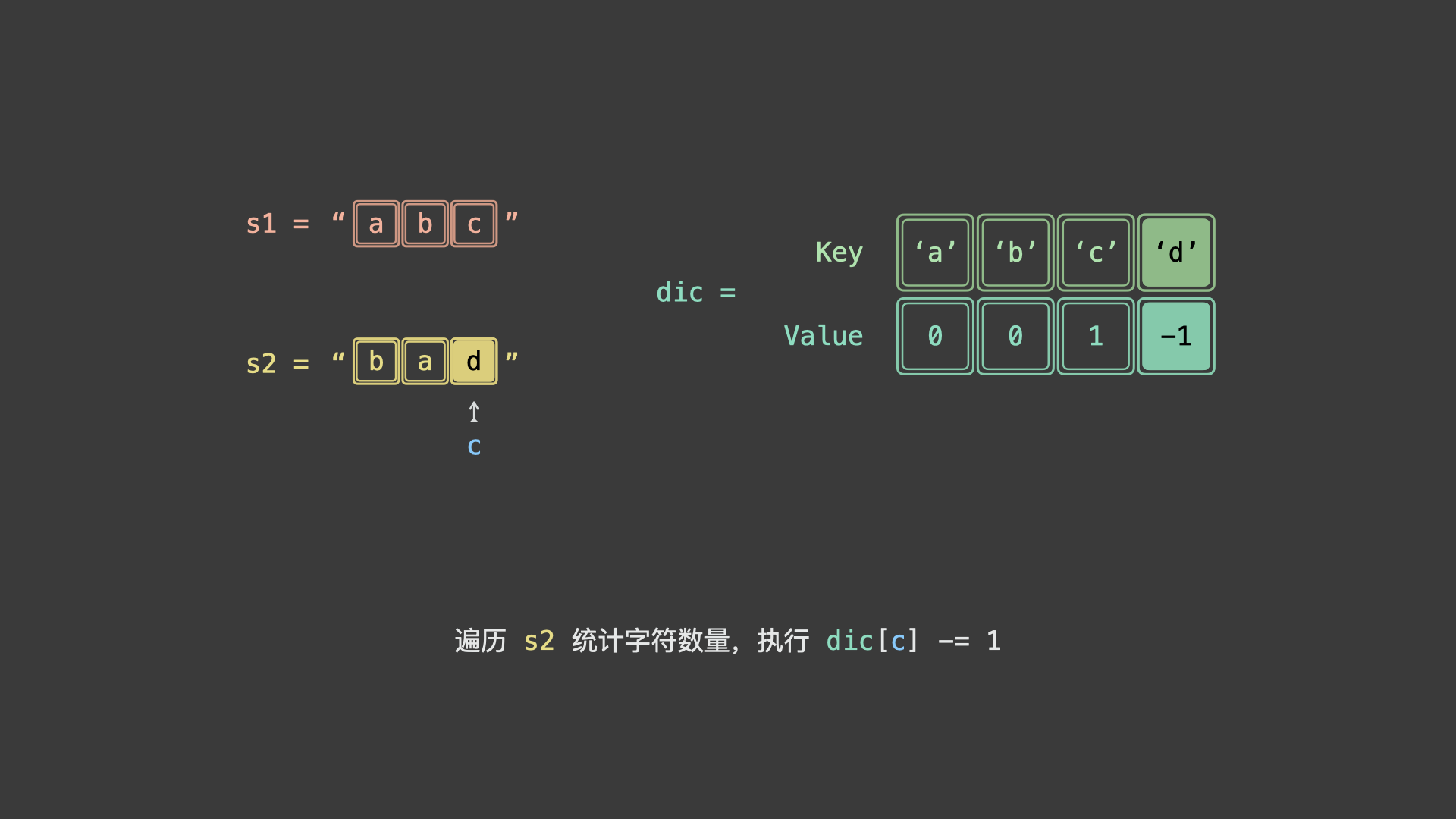
具体上看,我们可以统计 $s_1$ 各字符时执行 $+1$ ,统计 $s_2$ 各字符时 $-1$ 。若两字符串互为重排,则最终哈希表中所有字符统计数值都应为 0 。
如下图所示,为 $s_1 = "abc"$ , $s_2 = "bad"$ 的算法执行过程。
< ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, >
>
代码:
Python 代码使用 collections.defaultdict() 类,可指定所有 key 对应的默认 value 。
后三个 Tab 为「代码注释解析」。
Python
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
if len(s) != len(t):
return False
dic = defaultdict(int)
for c in s:
dic[c] += 1
for c in t:
dic[c] -= 1
for val in dic.values():
if val != 0:
return False
return TrueJava
class Solution {
public boolean isAnagram(String s, String t) {
int len1 = s.length(), len2 = t.length();
if (len1 != len2)
return false;
HashMap<Character, Integer> dic = new HashMap<>();
for (int i = 0; i < len1; i++) {
dic.put(s.charAt(i) , dic.getOrDefault(s.charAt(i), 0) + 1);
}
for (int i = 0; i < len2; i++) {
dic.put(t.charAt(i) , dic.getOrDefault(t.charAt(i), 0) - 1);
}
for (int val : dic.values()) {
if (val != 0)
return false;
}
return true;
}
}C++
class Solution {
public:
bool isAnagram(string s, string t) {
if (s.length() != t.length())
return false;
unordered_map<char, int> dic;
for (char c : s) {
dic[c] += 1;
}
for (char c : t) {
dic[c] -= 1;
}
for (auto kv : dic) {
if (kv.second != 0)
return false;
}
return true;
}
};Python
class Solution:
def isAnagram(self, s: str, t: str) -> bool:
# 若 s, t 长度不同,则不互为重排
if len(s) != len(t):
return False
# 初始化字典 dic ,且所有 key 的初始 value 都为 0
dic = defaultdict(int)
# 统计字符串 s 各字符数量,遇到 +1
for c in s:
dic[c] += 1
# 统计字符串 t 各字符数量,遇到 -1
for c in t:
dic[c] -= 1
# 遍历 s, t 中各字符的数量差
for val in dic.values():
# 若 s, t 中某字符的数量不一致,则不互为重排
if val != 0:
return False
# 所有字符数量都一致,因此互为重排
return TrueJava
class Solution {
public boolean isAnagram(String s, String t) {
int len1 = s.length(), len2 = t.length();
// 若 s, t 长度不同,则不互为重排
if (len1 != len2)
return false;
// 初始化哈希表 dic
HashMap<Character, Integer> dic = new HashMap<>();
// 统计字符串 s 各字符数量,遇到 +1
for (int i = 0; i < len1; i++) {
// dic.getOrDefault(key, default) 函数:在 key 存在时返回对应 value ,在 key 不存在时默认返回 default 值;
dic.put(s.charAt(i) , dic.getOrDefault(s.charAt(i), 0) + 1);
}
// 统计字符串 t 各字符数量,遇到 -1
for (int i = 0; i < len2; i++) {
dic.put(t.charAt(i) , dic.getOrDefault(t.charAt(i), 0) - 1);
}
// 遍历 s, t 中各字符的数量差
for (int val : dic.values()) {
// 若 s, t 中某字符的数量不一致,则不互为重排
if (val != 0)
return false;
}
// 所有字符数量都一致,因此互为重排
return true;
}
}C++
class Solution {
public:
bool isAnagram(string s, string t) {
// 若 s, t 长度不同,则不互为重排
if (s.length() != t.length())
return false;
// 初始化哈希表 dic
unordered_map<char, int> dic;
// 统计字符串 s 各字符数量,遇到 +1
for (char c : s) {
dic[c] += 1;
}
// 统计字符串 t 各字符数量,遇到 -1
for (char c : t) {
dic[c] -= 1;
}
// 遍历 s, t 中各字符的数量差
for (auto kv : dic) {
// 若 s, t 中某字符的数量不一致,则不互为重排
if (kv.second != 0)
return false;
}
// 所有字符数量都一致,因此互为重排
return true;
}
};复杂度分析:
时间复杂度 $O(M + N)$ : 其 $M$ , $N$ 分别为字符串 $s_1$ , $s_2$ 长度。当 $s_1$ , $s_2$ 无相同字符时,三轮循环的总迭代次数最多为 $2M + 2N$ ,使用 $O(M + N)$ 线性时间。
空间复杂度 $O(1)$ : 由于字符种类是有限的(常量),一般 ASCII 码共包含 128 个字符,因此可假设使用 $O(1)$ 大小的额外空间。