解题思路:
本问题是典型的回溯问题,可使用 深度优先搜索(DFS)+ 剪枝 解决。
- 深度优先搜索: 可以理解为暴力法遍历矩阵中所有字符串可能性。DFS 通过递归,先朝一个方向搜到底,再回溯至上个节点,沿另一个方向搜索,以此类推。
- 剪枝: 在搜索中,遇到
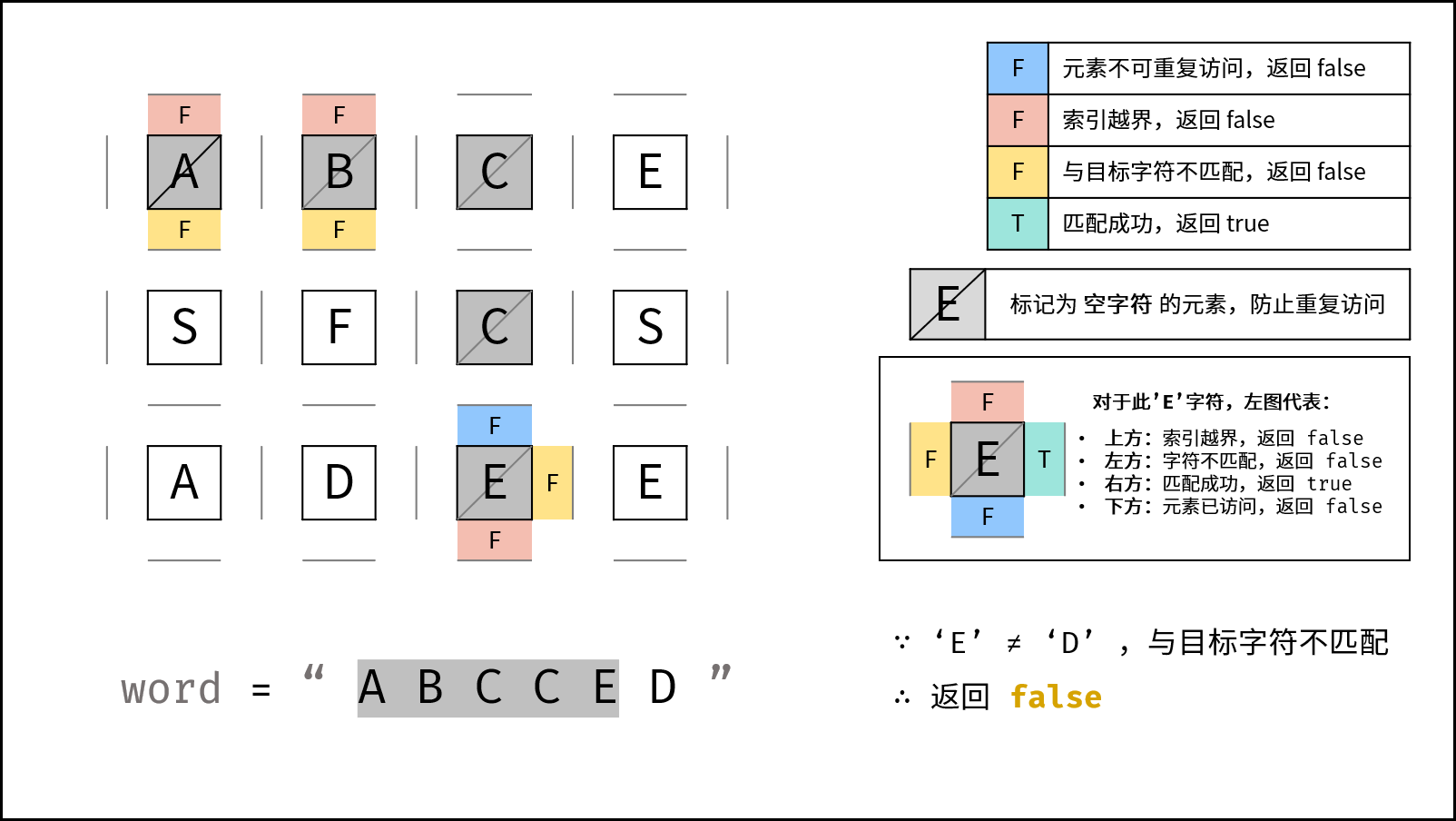
这条路不可能和目标字符串匹配成功的情况(例如:此矩阵元素和目标字符不同、此元素已被访问),则应立即返回,称之为可行性剪枝。
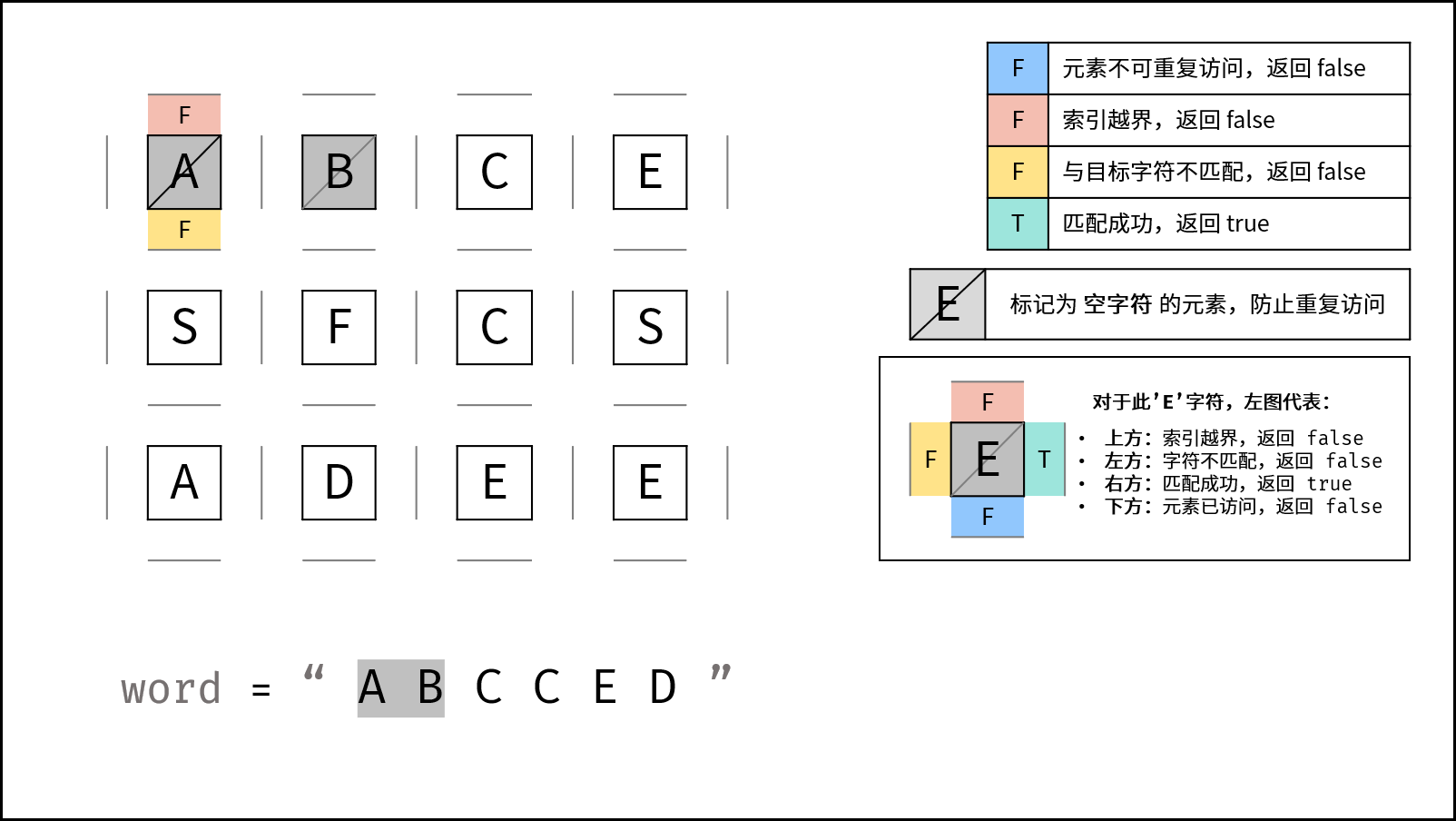
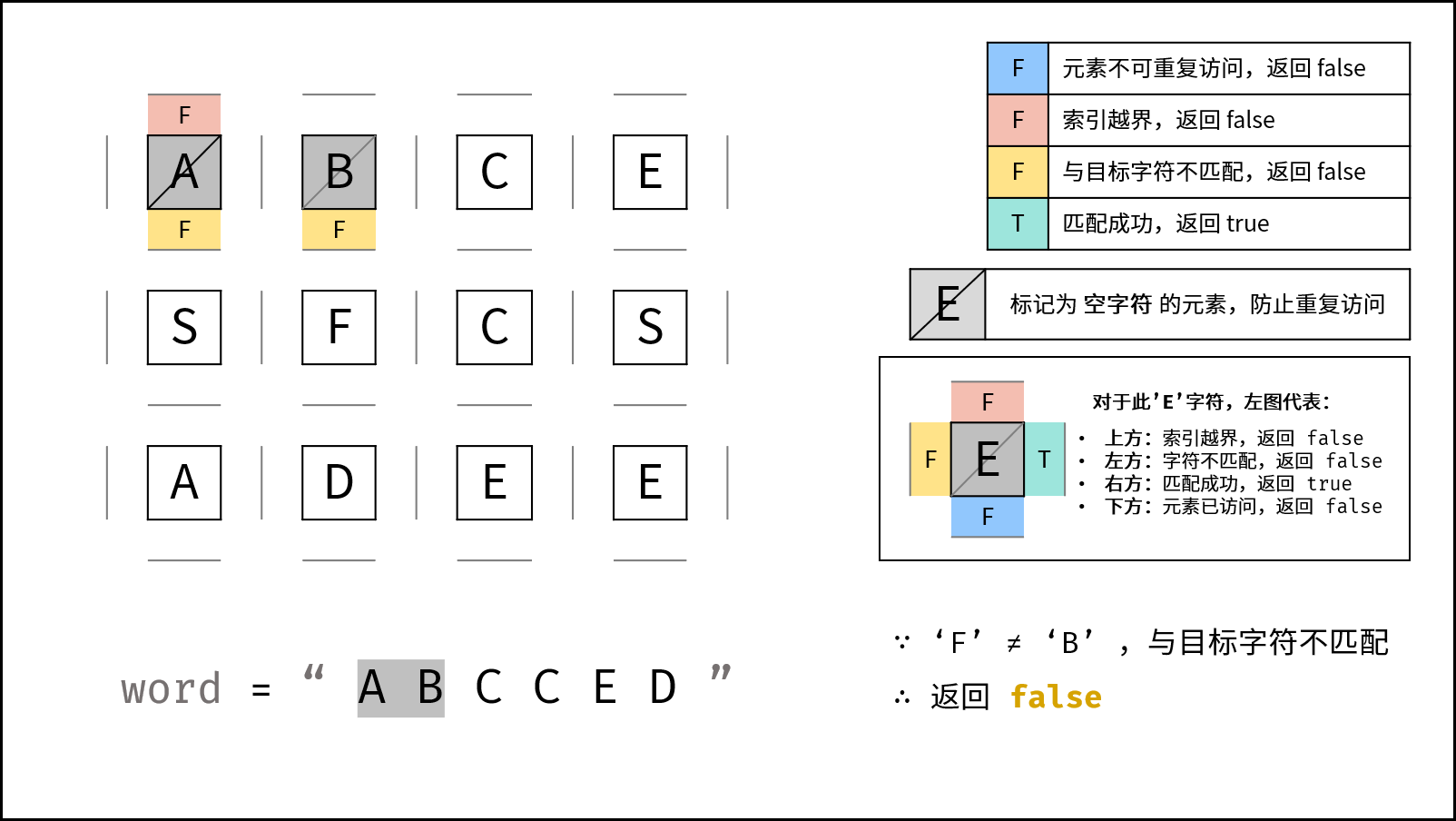
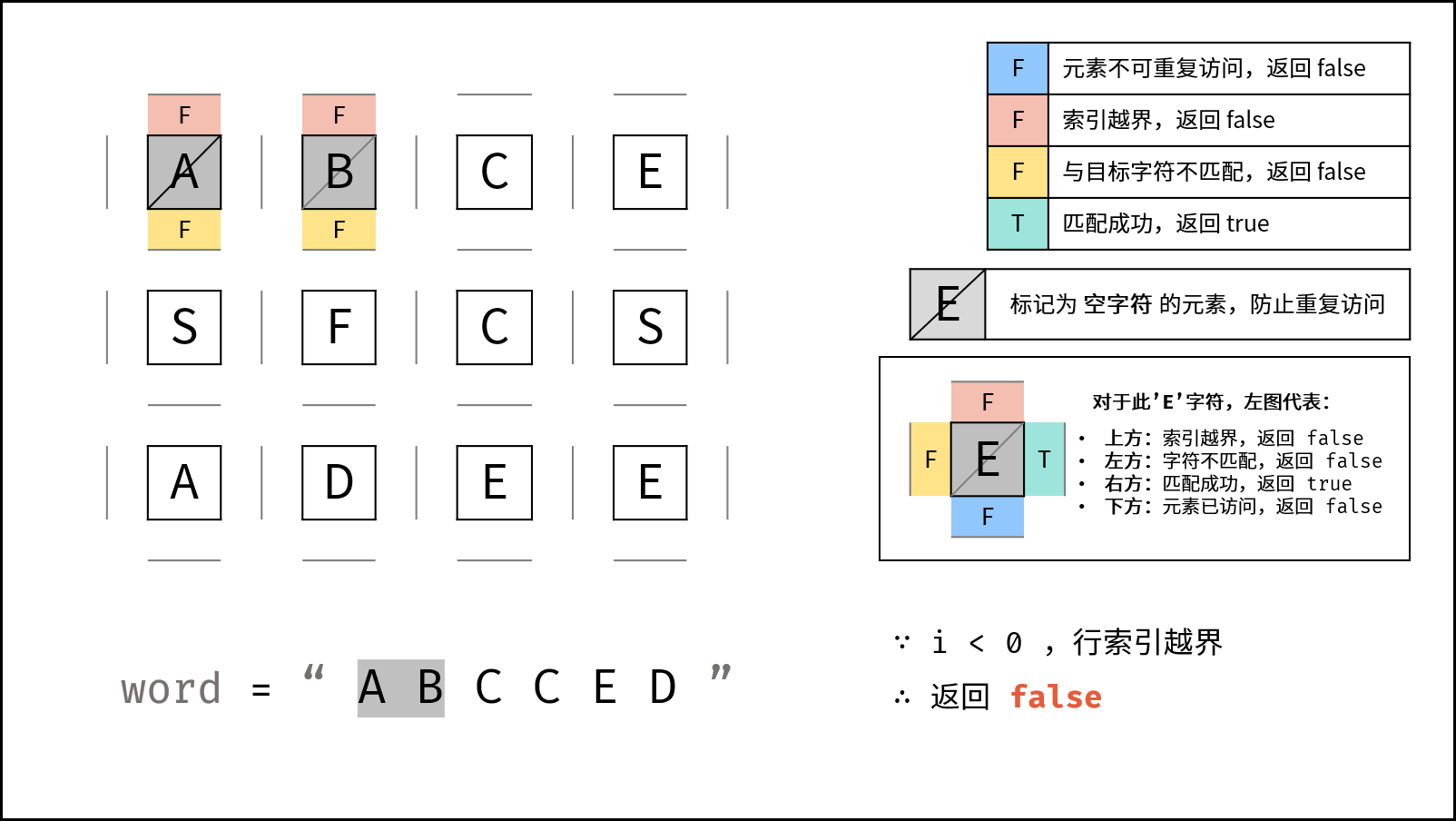
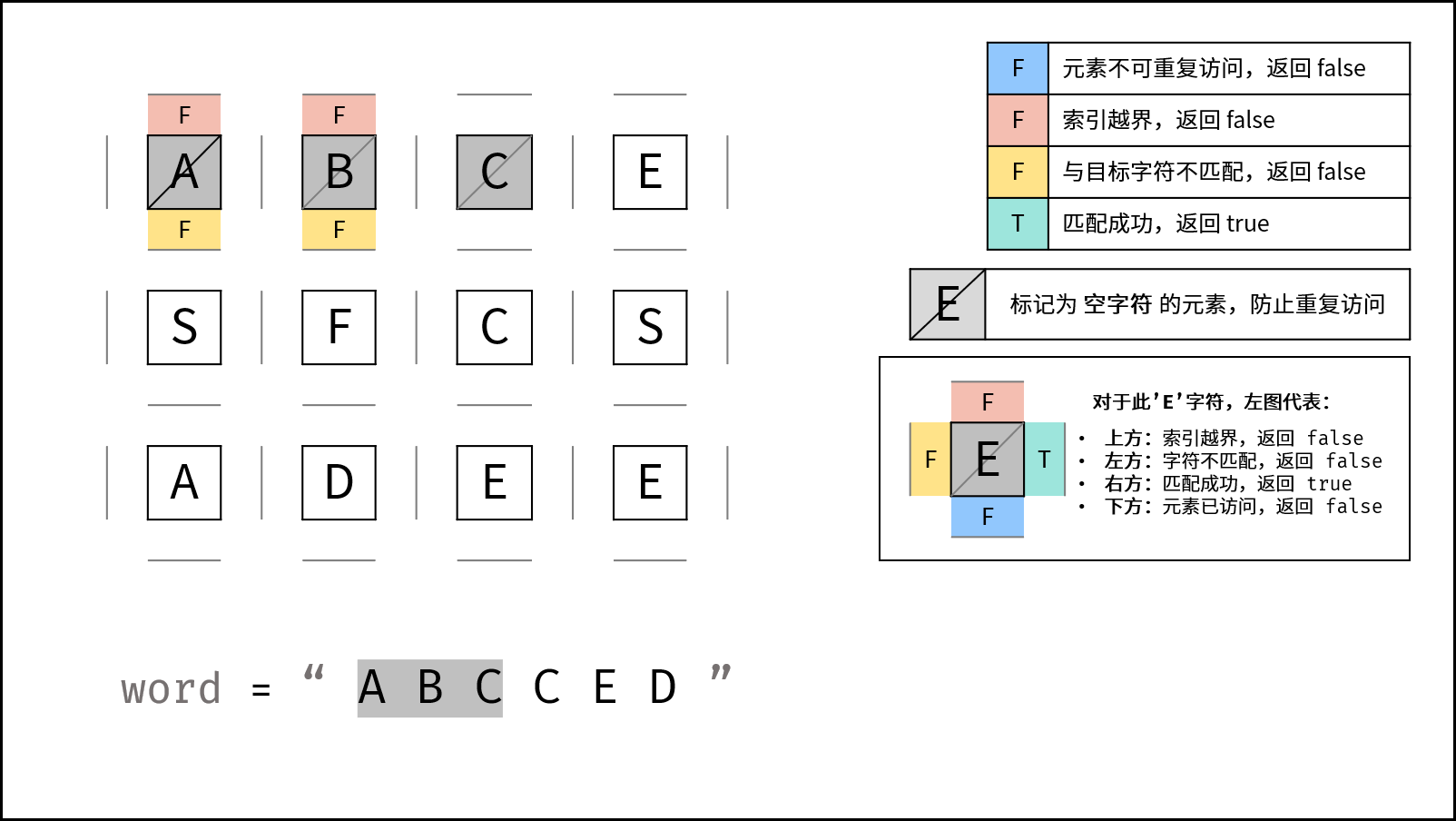
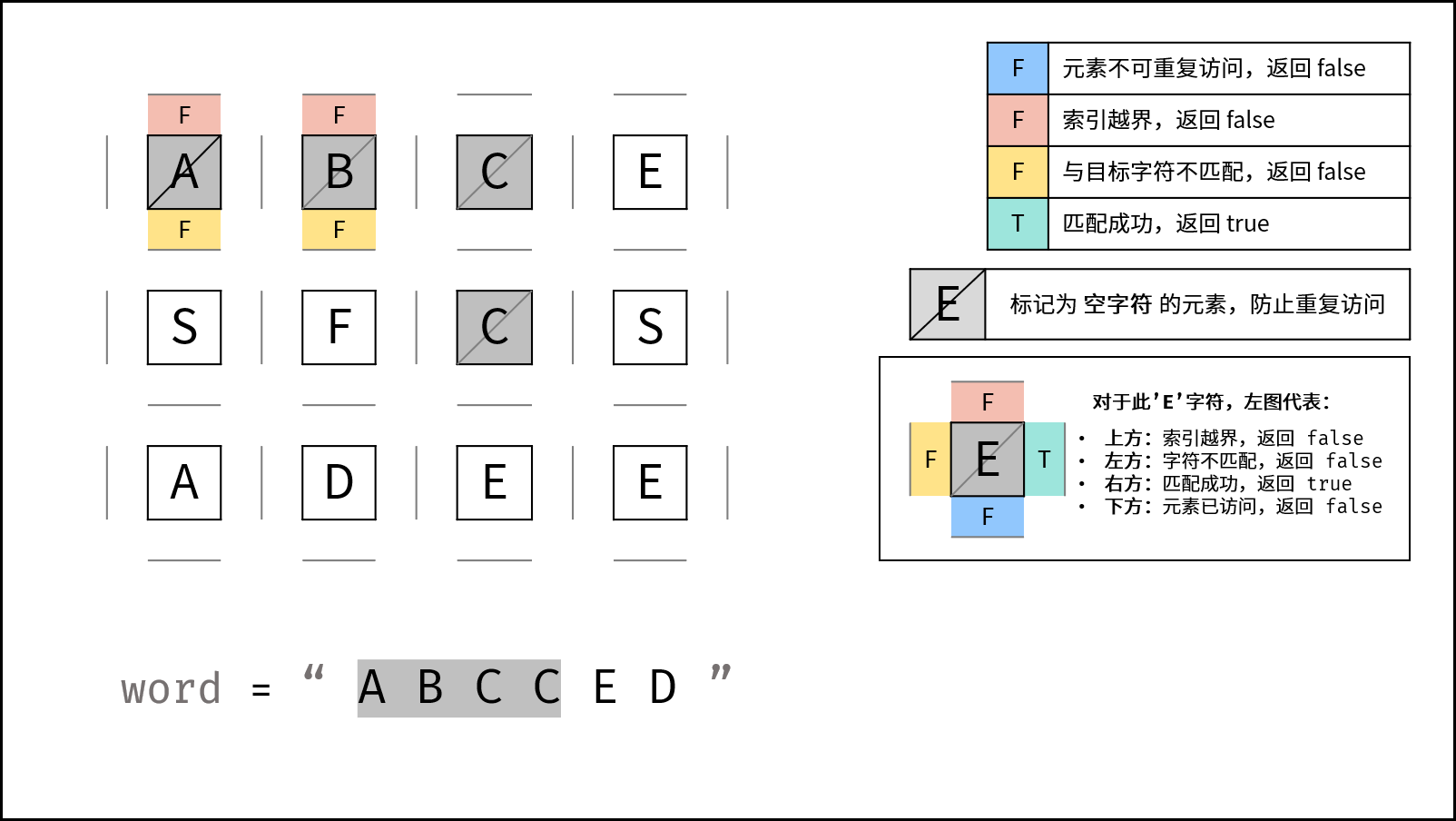
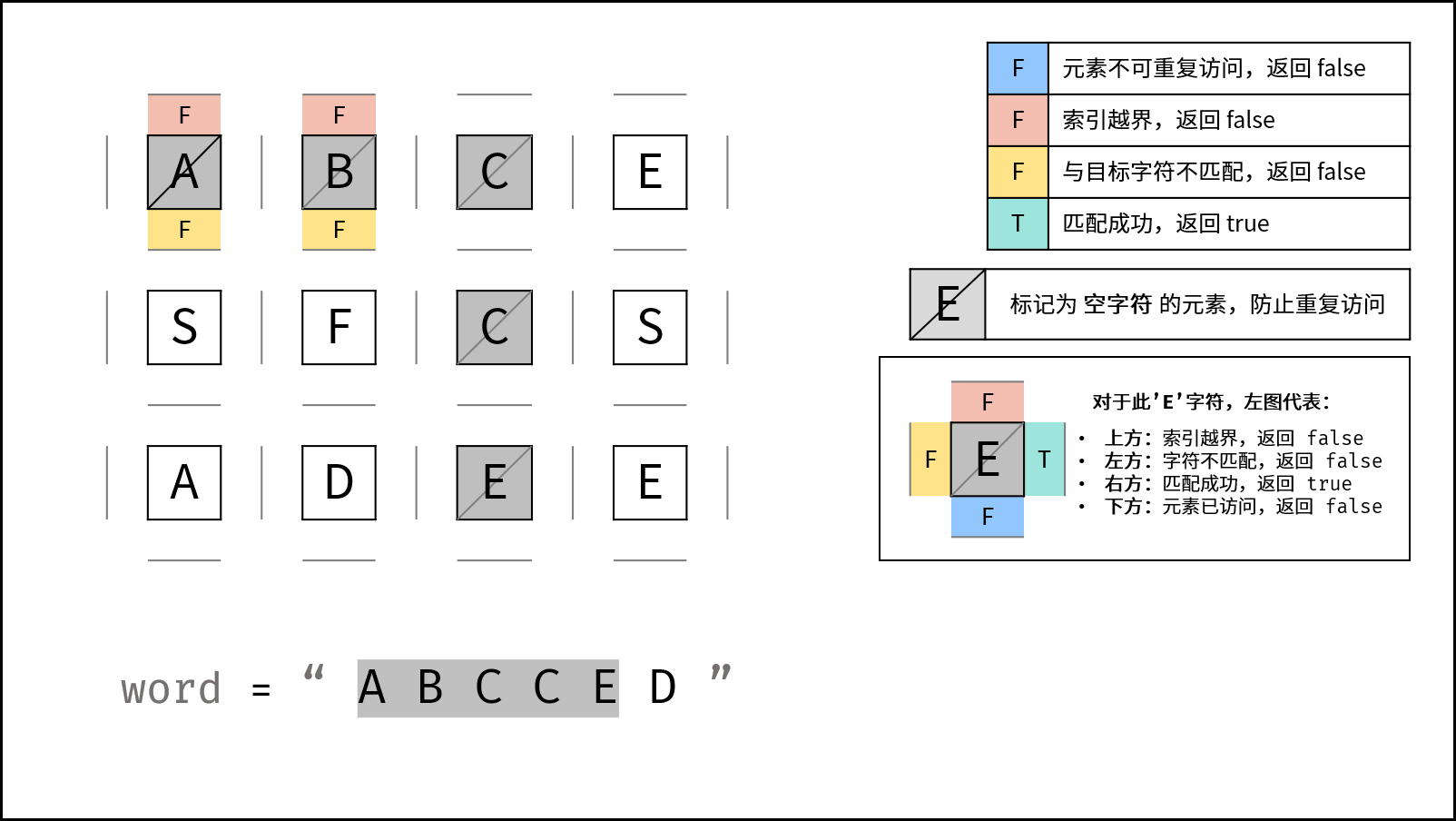
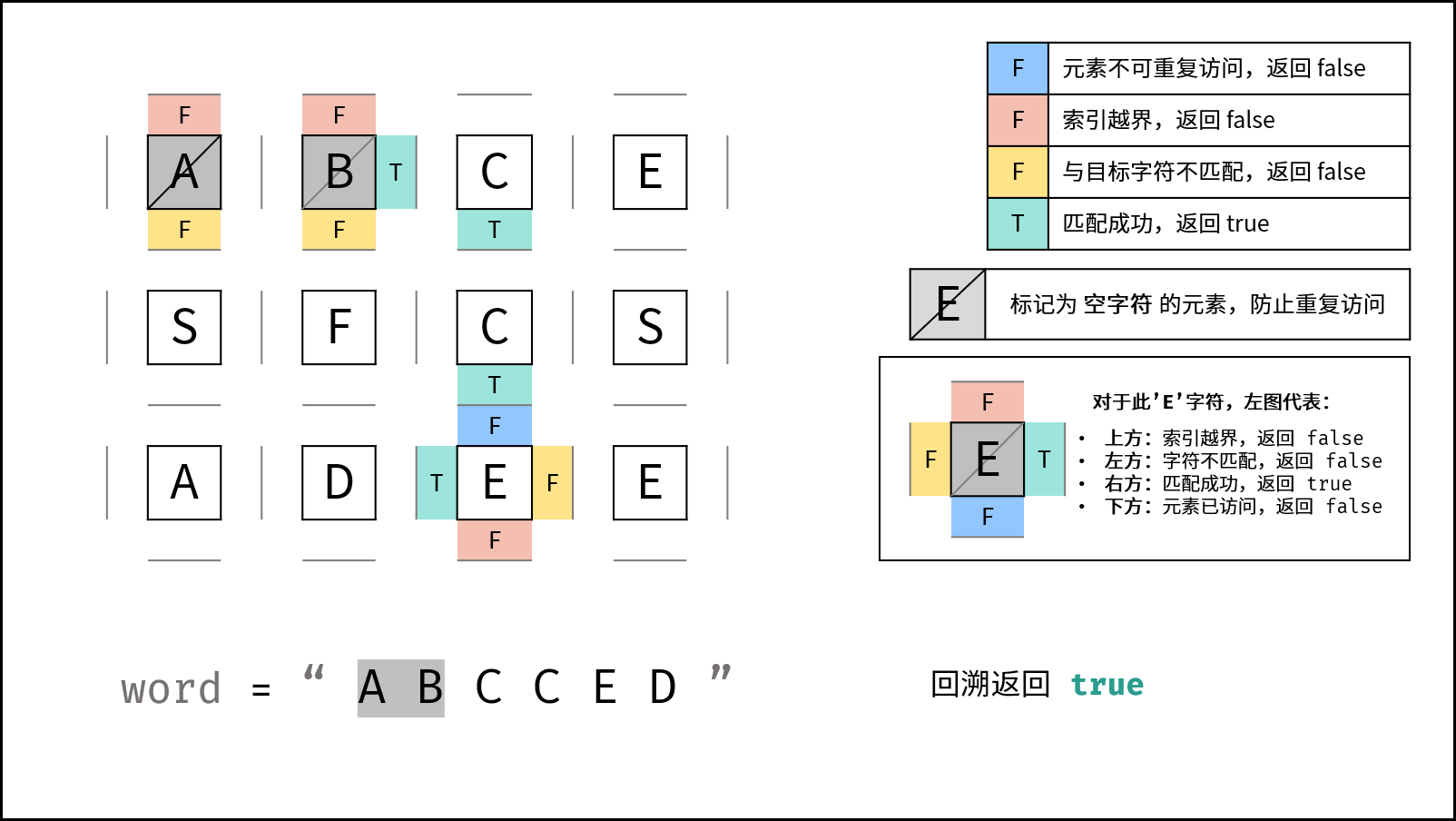
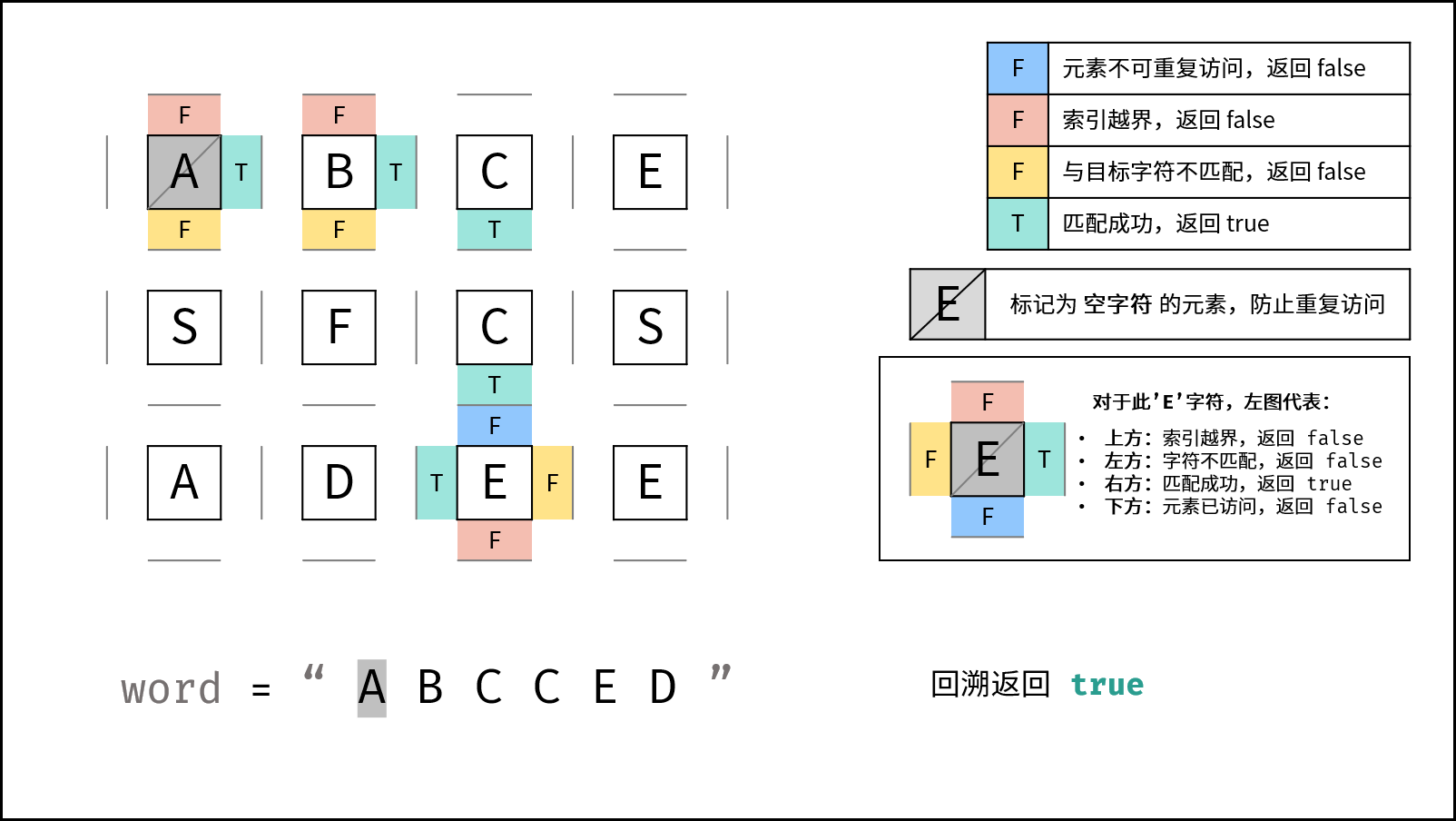
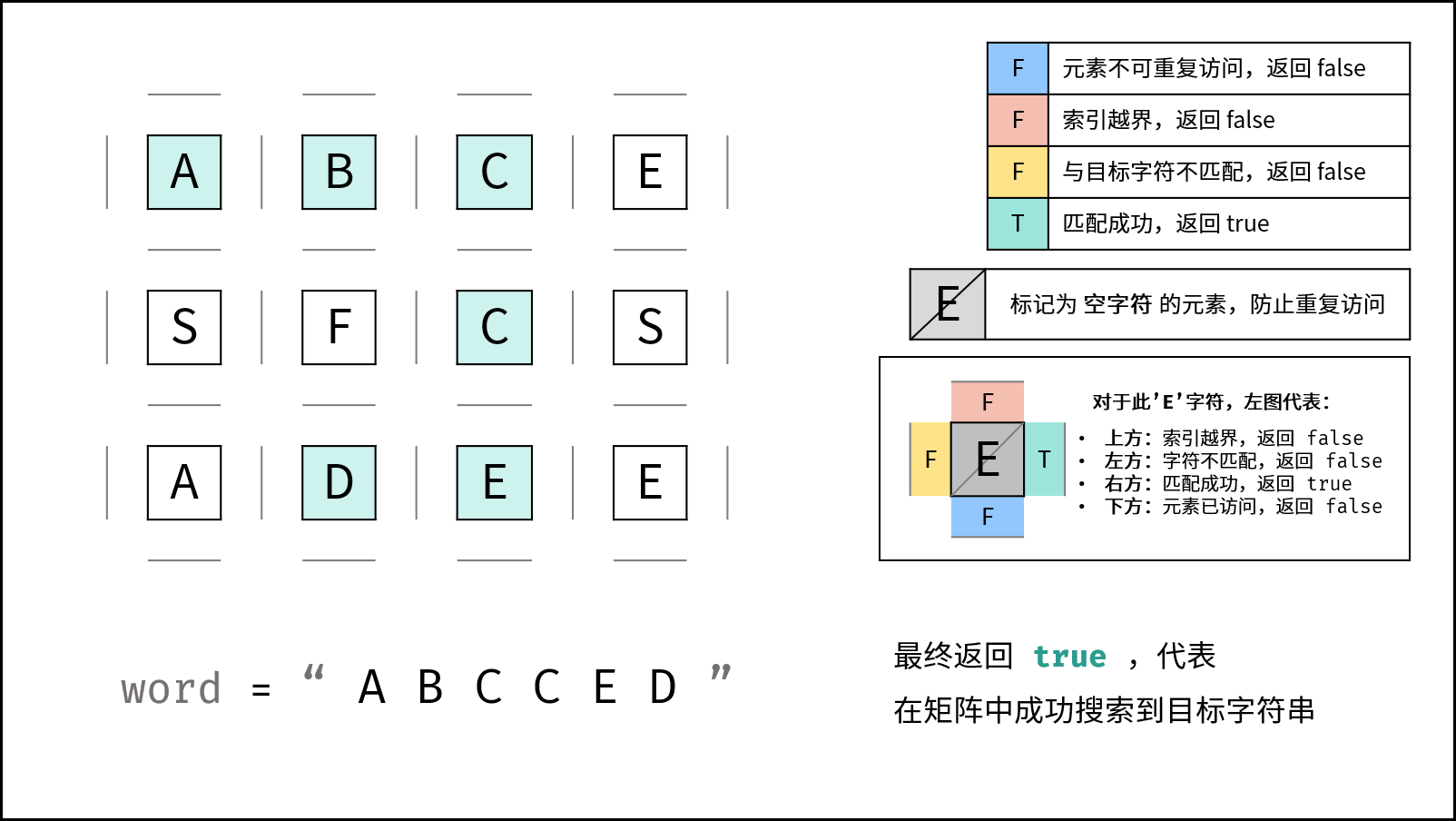
下图中的
word对应本题的target。
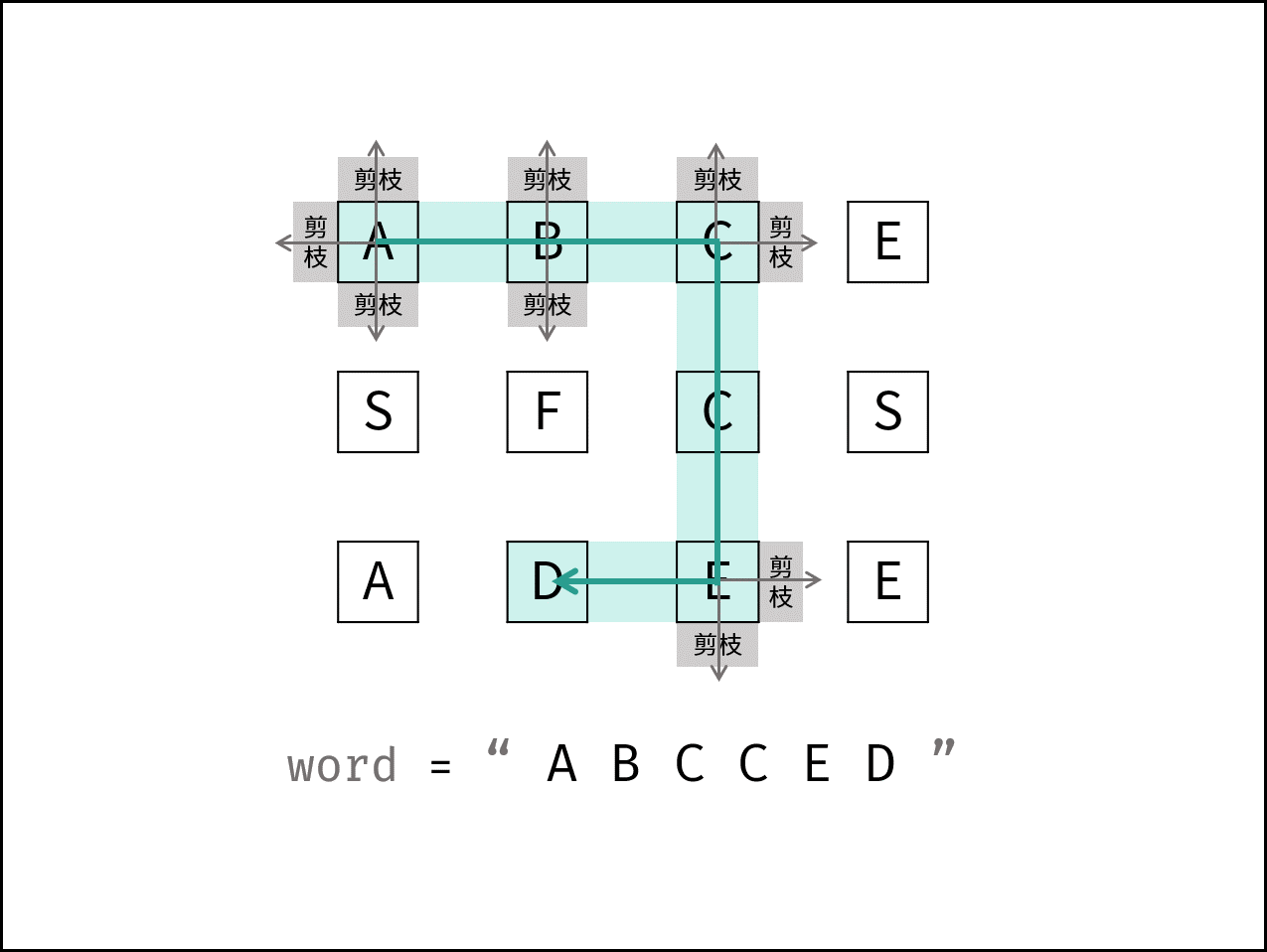
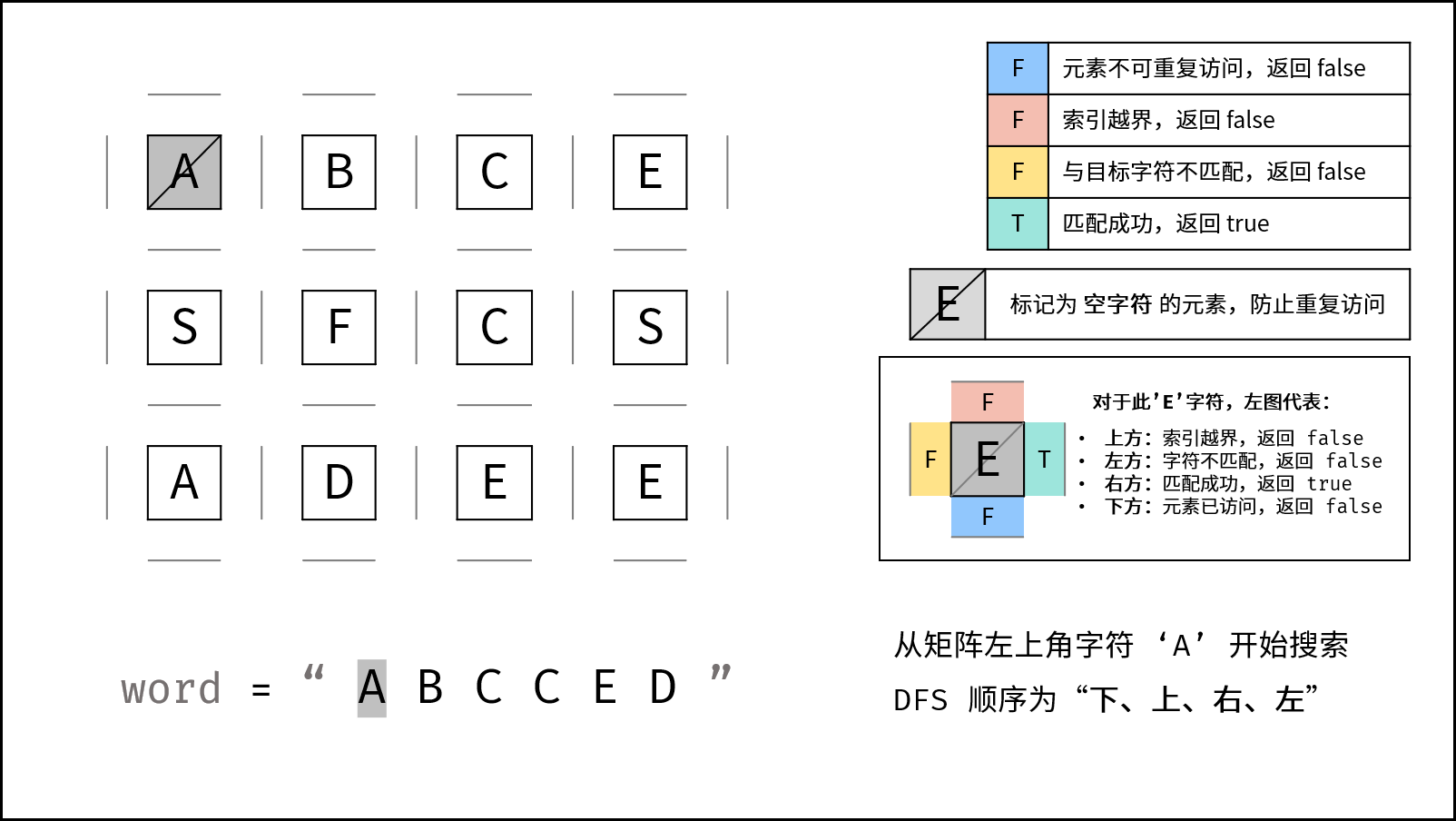
DFS 解析:
- 递归参数: 当前元素在矩阵
grid中的行列索引i和j,当前目标字符在target中的索引k。 - 终止条件:
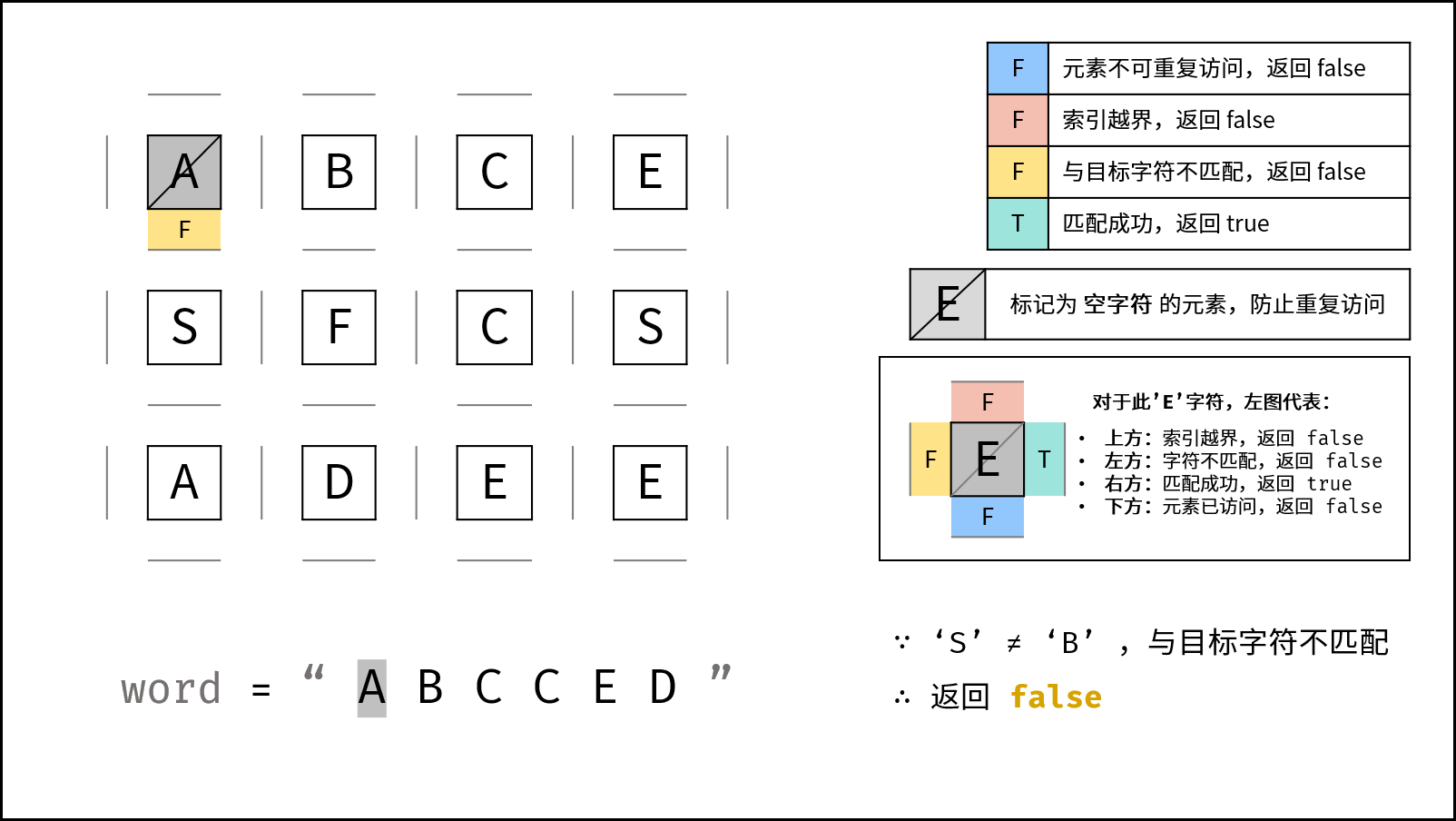
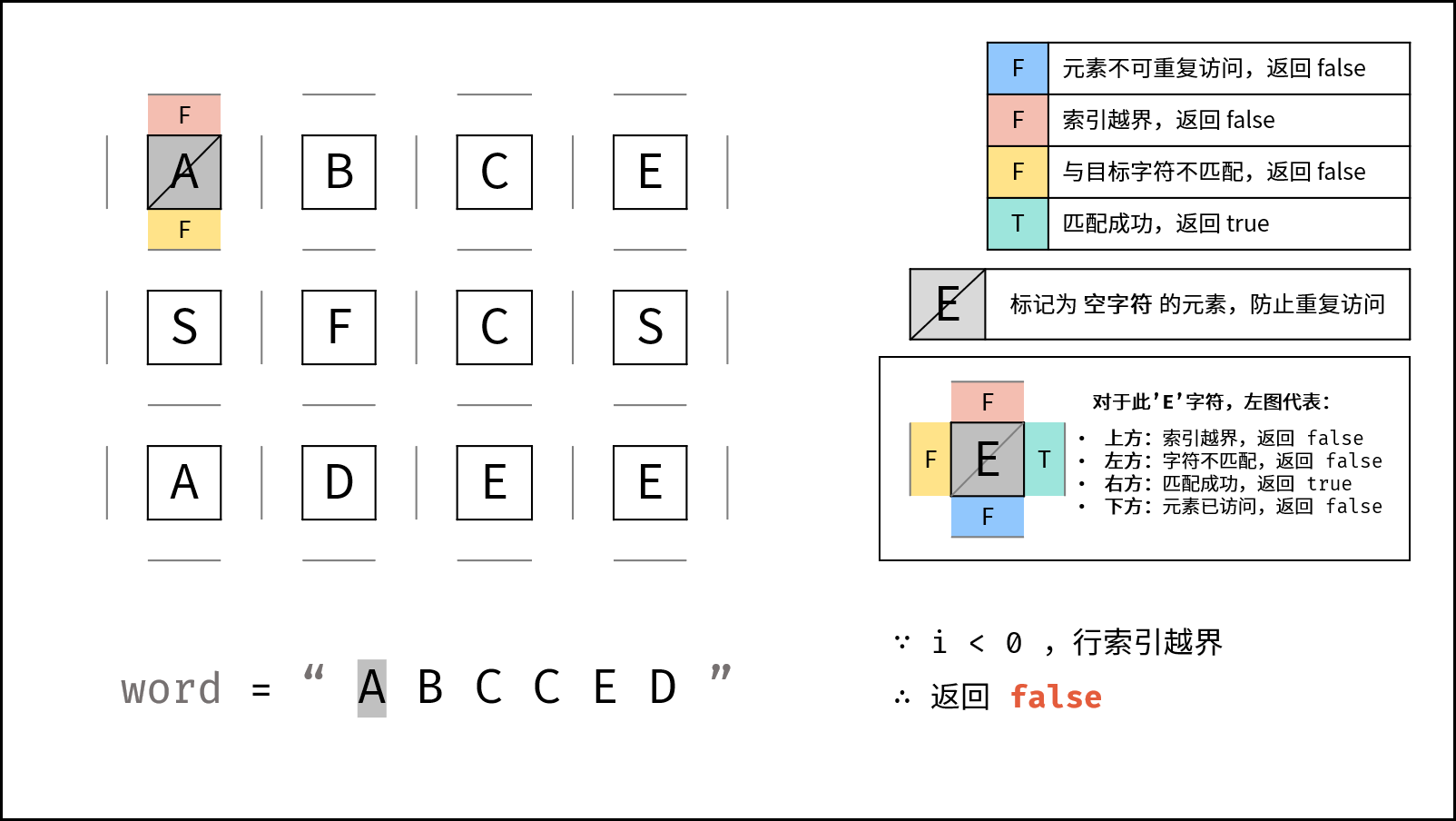
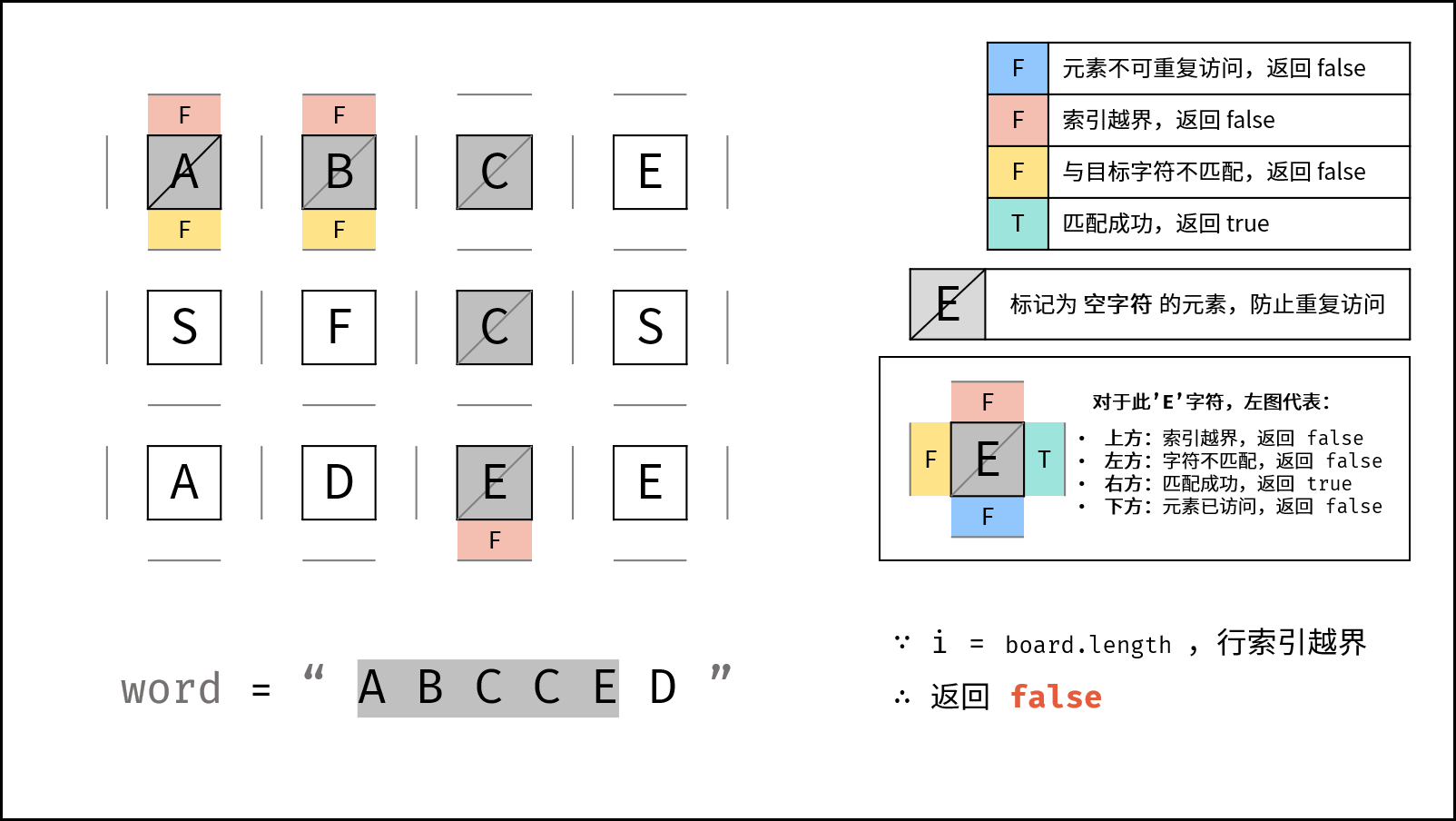
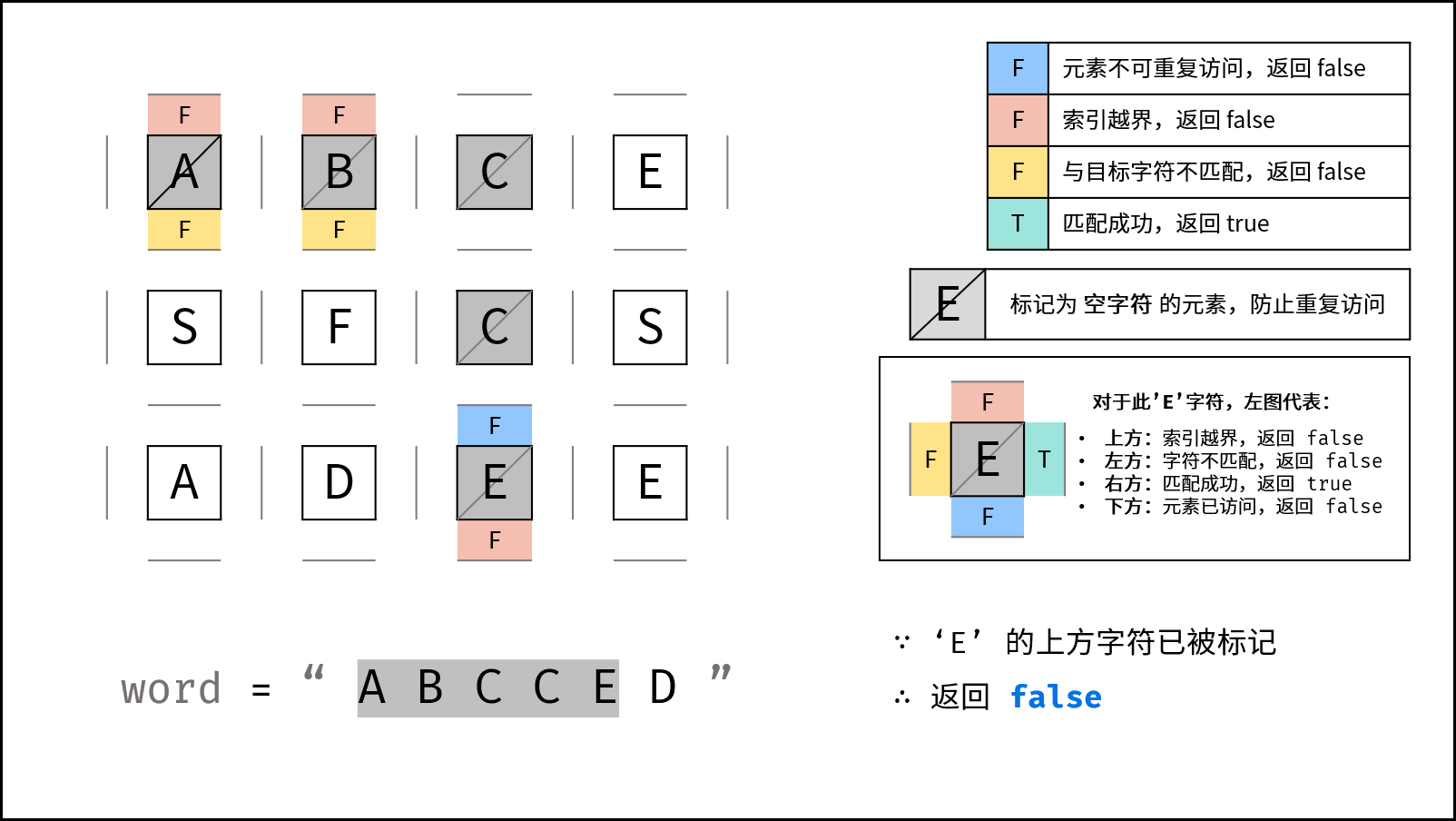
- 返回 $\text{false}$ : (1) 行或列索引越界 或 (2) 当前矩阵元素与目标字符不同 或 (3) 当前矩阵元素已访问过 ( (3) 可合并至 (2) ) 。
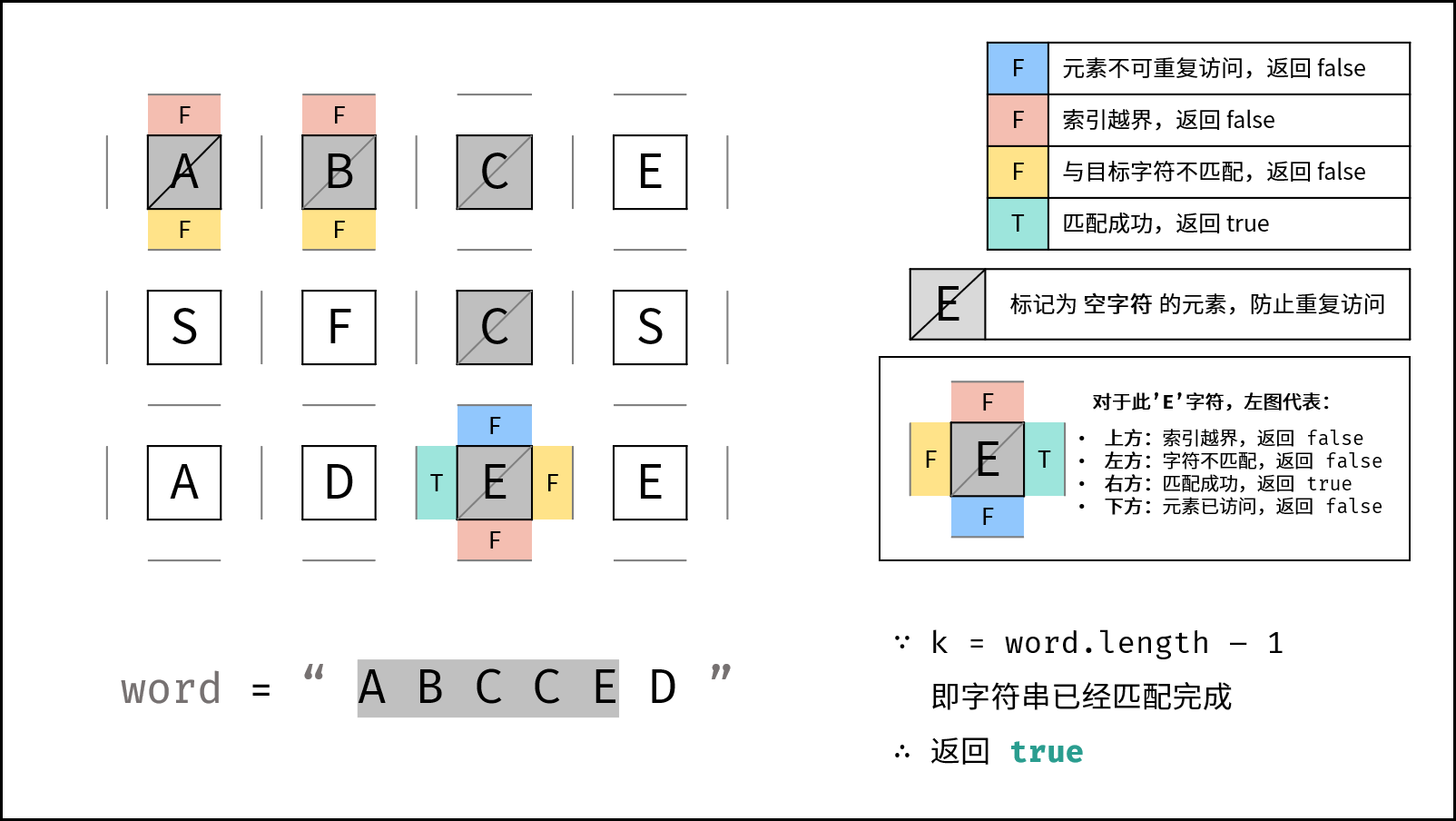
- 返回 $\text{true}$ :
k = len(target) - 1,即字符串target已全部匹配。
- 递推工作:
- 标记当前矩阵元素: 将
grid[i][j]修改为 空字符'',代表此元素已访问过,防止之后搜索时重复访问。 - 搜索下一单元格: 朝当前元素的 上、下、左、右 四个方向开启下层递归,使用
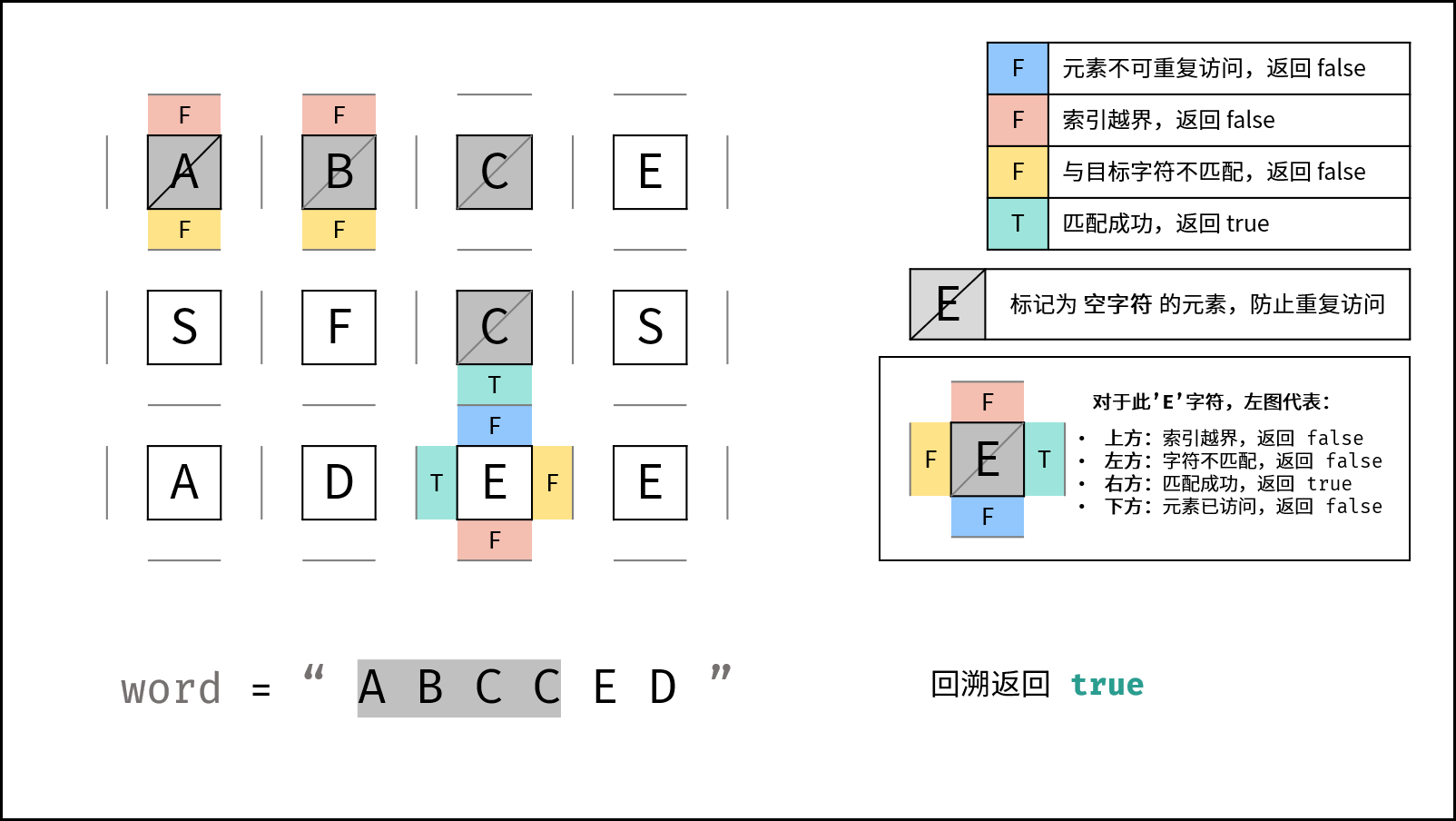
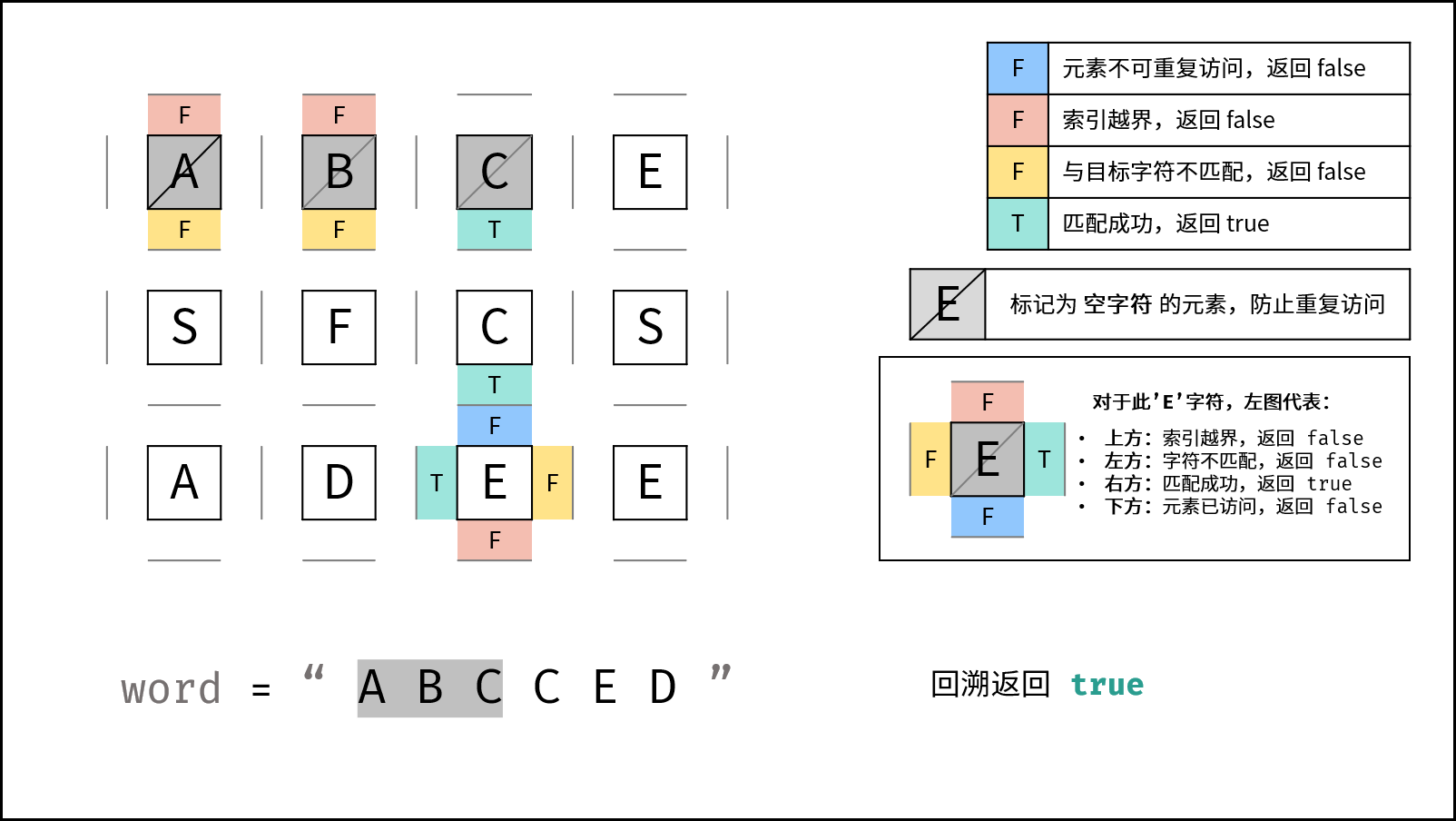
或连接 (代表只需找到一条可行路径就直接返回,不再做后续 DFS ),并记录结果至res。 - 还原当前矩阵元素: 将
grid[i][j]元素还原至初始值,即target[k]。
- 标记当前矩阵元素: 将
- 返回值: 返回布尔量
res,代表是否搜索到目标字符串。
使用空字符(Python:
'', Java/C++:'\0')做标记是为了防止标记字符与矩阵原有字符重复。当存在重复时,此算法会将矩阵原有字符认作标记字符,从而出现错误。
< ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, ,
, >
>
代码:
Python
class Solution:
def wordPuzzle(self, grid: List[List[str]], target: str) -> bool:
def dfs(i, j, k):
if not 0 <= i < len(grid) or not 0 <= j < len(grid[0]) or grid[i][j] != target[k]: return False
if k == len(target) - 1: return True
grid[i][j] = ''
res = dfs(i + 1, j, k + 1) or dfs(i - 1, j, k + 1) or dfs(i, j + 1, k + 1) or dfs(i, j - 1, k + 1)
grid[i][j] = target[k]
return res
for i in range(len(grid)):
for j in range(len(grid[0])):
if dfs(i, j, 0): return True
return FalseJava
class Solution {
public boolean wordPuzzle(char[][] grid, String target) {
char[] words = target.toCharArray();
for(int i = 0; i < grid.length; i++) {
for(int j = 0; j < grid[0].length; j++) {
if(dfs(grid, words, i, j, 0)) return true;
}
}
return false;
}
boolean dfs(char[][] grid, char[] target, int i, int j, int k) {
if(i >= grid.length || i < 0 || j >= grid[0].length || j < 0 || grid[i][j] != target[k]) return false;
if(k == target.length - 1) return true;
grid[i][j] = '\0';
boolean res = dfs(grid, target, i + 1, j, k + 1) || dfs(grid, target, i - 1, j, k + 1) ||
dfs(grid, target, i, j + 1, k + 1) || dfs(grid, target, i , j - 1, k + 1);
grid[i][j] = target[k];
return res;
}
}C++
class Solution {
public:
bool wordPuzzle(vector<vector<char>>& grid, string target) {
rows = grid.size();
cols = grid[0].size();
for(int i = 0; i < rows; i++) {
for(int j = 0; j < cols; j++) {
if(dfs(grid, target, i, j, 0)) return true;
}
}
return false;
}
private:
int rows, cols;
bool dfs(vector<vector<char>>& grid, string target, int i, int j, int k) {
if(i >= rows || i < 0 || j >= cols || j < 0 || grid[i][j] != target[k]) return false;
if(k == target.size() - 1) return true;
grid[i][j] = '\0';
bool res = dfs(grid, target, i + 1, j, k + 1) || dfs(grid, target, i - 1, j, k + 1) ||
dfs(grid, target, i, j + 1, k + 1) || dfs(grid, target, i , j - 1, k + 1);
grid[i][j] = target[k];
return res;
}
};复杂度分析:
$M, N$ 分别为矩阵行列大小,$K$ 为字符串
target长度。
- 时间复杂度 $O(3^KMN)$ : 最差情况下,需要遍历矩阵中长度为 $K$ 字符串的所有方案,时间复杂度为 $O(3^K)$;矩阵中共有 $MN$ 个起点,时间复杂度为 $O(MN)$ 。
- 方案数计算: 设字符串长度为 $K$ ,搜索中每个字符有上、下、左、右四个方向可以选择,舍弃回头(上个字符)的方向,剩下 $3$ 种选择,因此方案数的复杂度为 $O(3^K)$ 。
- 空间复杂度 $O(K)$ : 搜索过程中的递归深度不超过 $K$ ,因此系统因函数调用累计使用的栈空间占用 $O(K)$ (因为函数返回后,系统调用的栈空间会释放)。最坏情况下 $K = MN$ ,递归深度为 $MN$ ,此时系统栈使用 $O(MN)$ 的额外空间。